- 文章标题:Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
- 文章地址:https://arxiv.org/abs/2301.13826
- TOG 2023
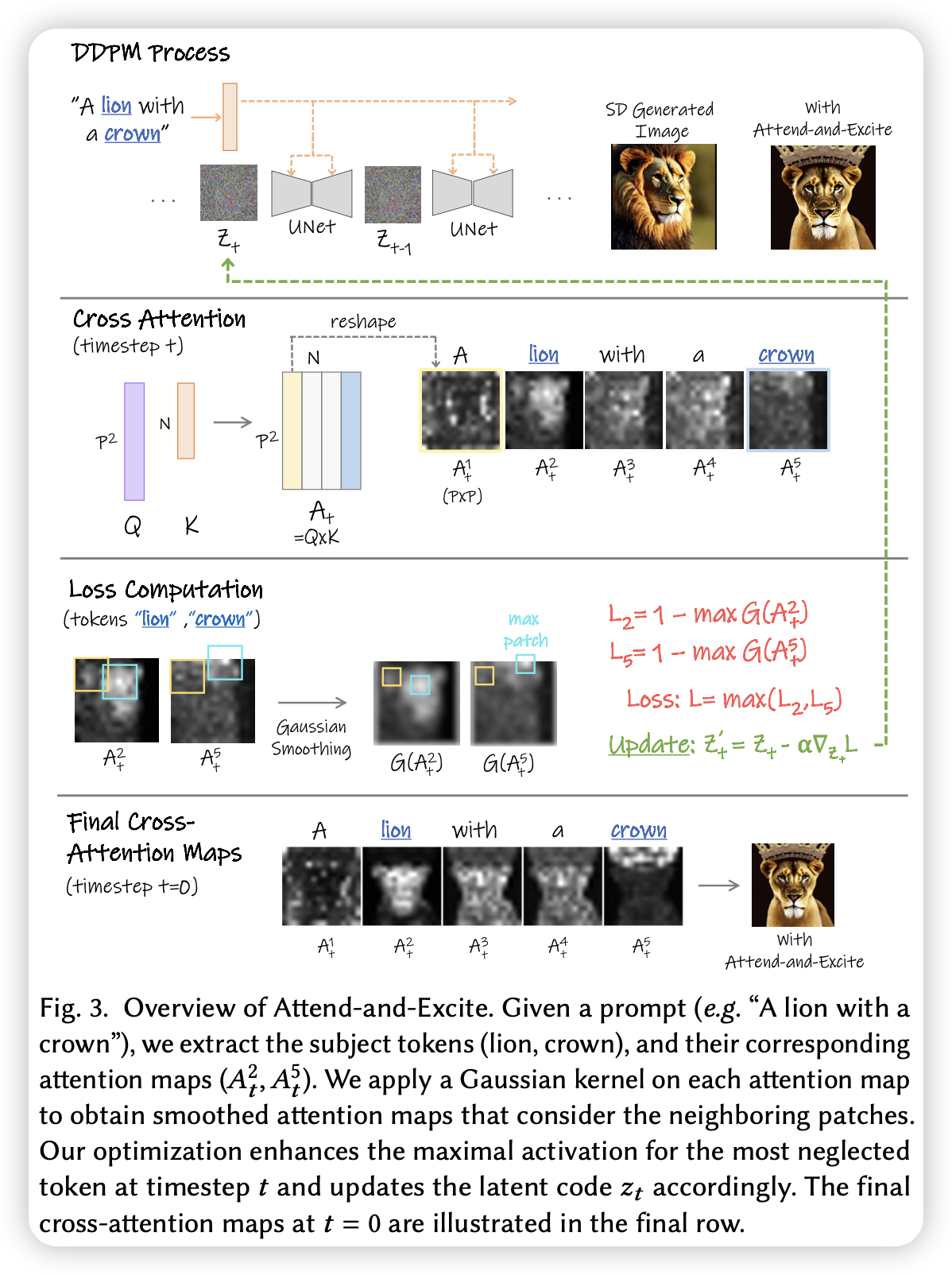 当前的文生图模型可能会在给定充分语义的prompt的图像生成中对某些对象或属性生成失败。例如:使用prompt生成不同属性的两个对象,模型可能会忽略某个对象或生成的属性出现错误。文章提出了Attend-and-Excite,驱使模型在推理阶段时,所有对象的token的attention map都有高亮的区域,从而驱使模型生成所有的对象。
该方法无需训练,在推理时完成。算法如下:
当前的文生图模型可能会在给定充分语义的prompt的图像生成中对某些对象或属性生成失败。例如:使用prompt生成不同属性的两个对象,模型可能会忽略某个对象或生成的属性出现错误。文章提出了Attend-and-Excite,驱使模型在推理阶段时,所有对象的token的attention map都有高亮的区域,从而驱使模型生成所有的对象。
该方法无需训练,在推理时完成。算法如下:
 效果图如下:
效果图如下:

- 数据:无需训练;测试数据自己构建了一个benchmark
- 指标:CLIP image-text相似度;CLIP text-text相似度(原prompt与生成图像的caption(BLIP2))
- 硬件:未提及
- 开源:https://yuval-alaluf.github.io/Attend-and-Excite/