- 文章标题:BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
- 文章地址:https://arxiv.org/abs/2305.14720
- NIPS 2024
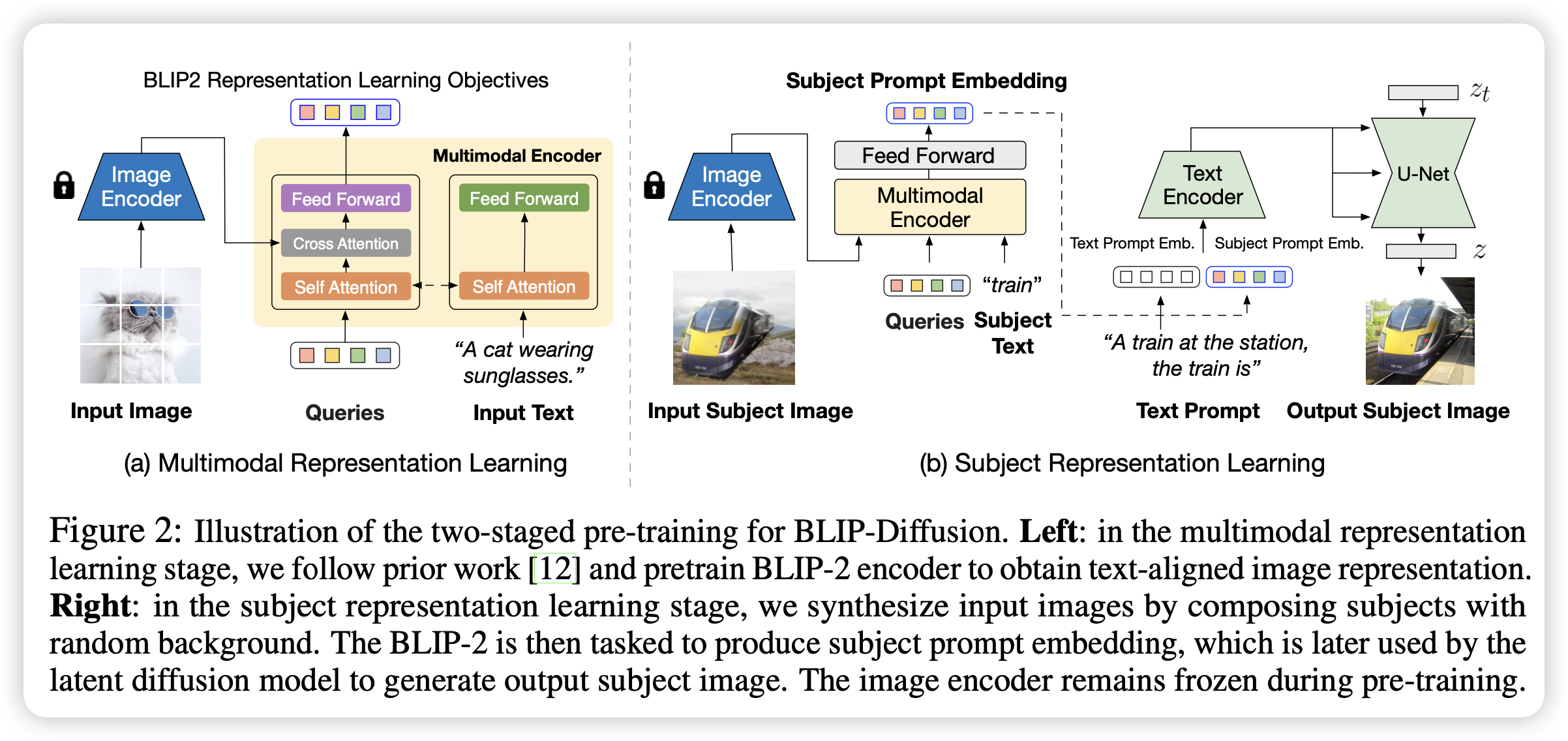 当前的对象驱动文生图现有的方法通常受限于很长的测试微调的时间和对象信息的保留度。为了解决这些问题,文章提出了BLIP-Diffusion,一种支持包含对象的图片和文本的多模态控制的对象驱动文生图模型。
模型根据BLIP-2提出了一个新的多模态编码器,并对其进行预训练,用于提取与文本对齐的视觉表示。然后作者设计了一个对象表示学习的任务,使得扩散模型可以根据该表示生成特定的对象。
相对于先前的模型,该方法支持zero-shot的生成或高效微调生成的方法。该框架可以与现有的基于基模型的方法共同使用。
当前的对象驱动文生图现有的方法通常受限于很长的测试微调的时间和对象信息的保留度。为了解决这些问题,文章提出了BLIP-Diffusion,一种支持包含对象的图片和文本的多模态控制的对象驱动文生图模型。
模型根据BLIP-2提出了一个新的多模态编码器,并对其进行预训练,用于提取与文本对齐的视觉表示。然后作者设计了一个对象表示学习的任务,使得扩散模型可以根据该表示生成特定的对象。
相对于先前的模型,该方法支持zero-shot的生成或高效微调生成的方法。该框架可以与现有的基于基模型的方法共同使用。

- 数据:LAION, COCO, Visual Genome, Conceptual Captions, OpenImage-V6
- 指标:DINO,CLIP-I,CLIP-T
- 硬件:16 A100/bs16
- 开源:https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion