- 文章标题:High-fidelity Person-centric Subject-to-Image Synthesis
- 文章地址:https://arxiv.org/abs/2311.10329
- CVPR 2024
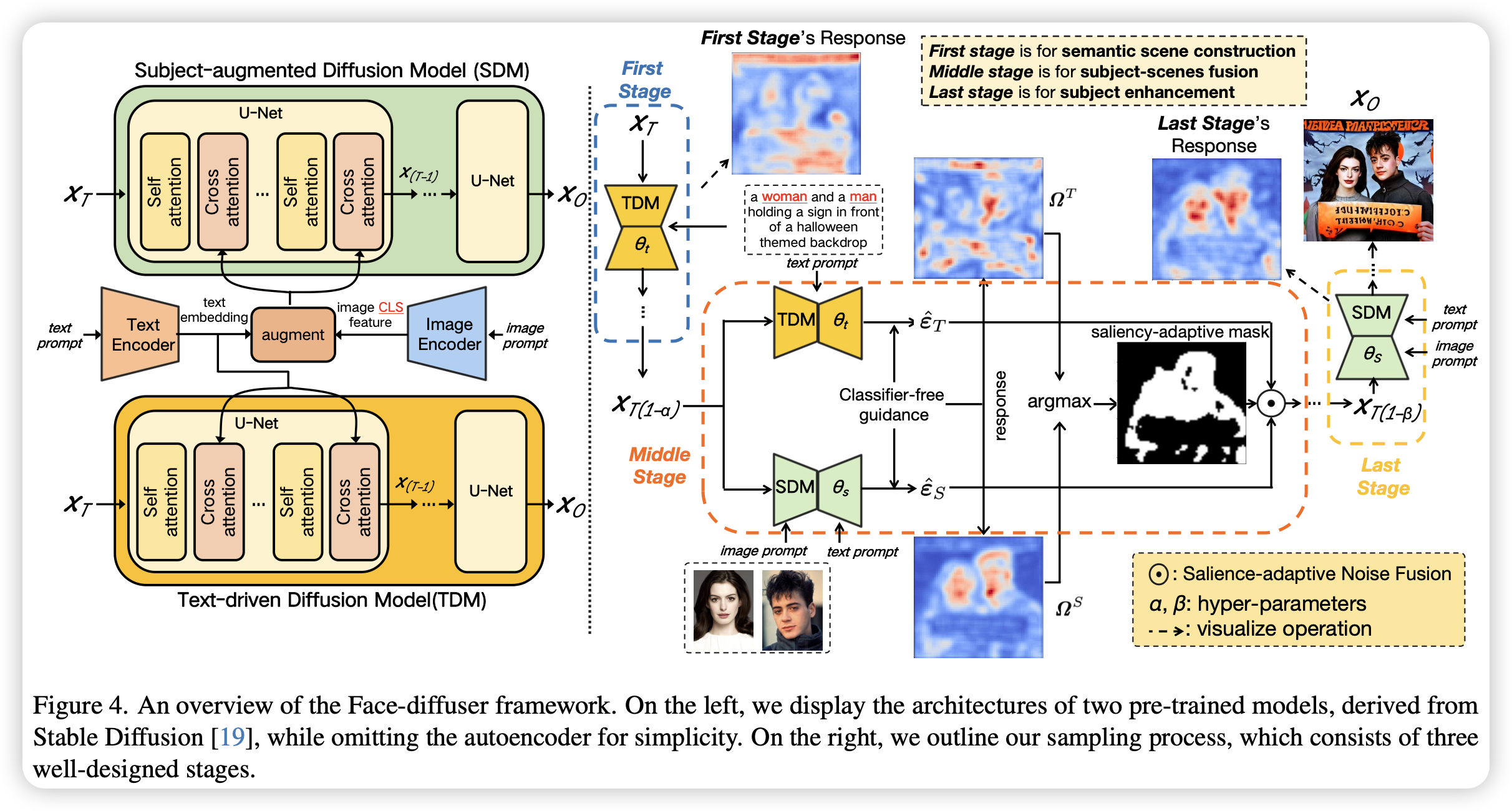 当前定制人脸的文生图模型面临一些挑战,因为这些方法通过微调一个普通的预训练的扩散模型来学习语义场景和人物生成,这其中蕴含了不可调和的不平衡训练。精确地说,要生成真实的人物图像,他们需要充分微调预训练的模型,这不可避免地导致模型忘记之前丰富的语义场景,并使其生成的场景过拟合。此外,即使充分微调后也无法生成高质量的人物,因为场景与人物生成的共同学习会造成质量的降低。这篇文章提出了Face-diffuser,一个有效的联合采样方法,可以消除上面的不平衡训练以及质量降低的情况。
具体来说,方法使用了两个模型,一个是SDM(经过定制人脸微调的模型),一个是TDM(文生图模型),分别负责人物和场景的生成。
采样阶段分成三个部分,首先是根据文本条件利用TDM进行语义场景的基本构建,第二个部分为对象-场景混合阶段,该阶段通过计算两个噪声差异(TDM的有文本与无文本模型的输出,SDM的有ID和无ID模型的输出)来判断哪些部分由TDM生成,哪些部分由SDM生成,然后使用掩码融合两者的输出,从而实现了对象-场景混合采样,第三个阶段是单独使用SDM进行更精细的人物生成。
当前定制人脸的文生图模型面临一些挑战,因为这些方法通过微调一个普通的预训练的扩散模型来学习语义场景和人物生成,这其中蕴含了不可调和的不平衡训练。精确地说,要生成真实的人物图像,他们需要充分微调预训练的模型,这不可避免地导致模型忘记之前丰富的语义场景,并使其生成的场景过拟合。此外,即使充分微调后也无法生成高质量的人物,因为场景与人物生成的共同学习会造成质量的降低。这篇文章提出了Face-diffuser,一个有效的联合采样方法,可以消除上面的不平衡训练以及质量降低的情况。
具体来说,方法使用了两个模型,一个是SDM(经过定制人脸微调的模型),一个是TDM(文生图模型),分别负责人物和场景的生成。
采样阶段分成三个部分,首先是根据文本条件利用TDM进行语义场景的基本构建,第二个部分为对象-场景混合阶段,该阶段通过计算两个噪声差异(TDM的有文本与无文本模型的输出,SDM的有ID和无ID模型的输出)来判断哪些部分由TDM生成,哪些部分由SDM生成,然后使用掩码融合两者的输出,从而实现了对象-场景混合采样,第三个阶段是单独使用SDM进行更精细的人物生成。

- 数据:FFHQ-Face;Single-benchmark dataset
- 指标:人脸相似性(faceNet);文本对齐度(CLIP)
- 硬件:4 A100/bs8
- 开源:https://github.com/CodeGoat24/Face-diffuser