- 文章标题:HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
- 文章地址:https://arxiv.org/abs/2106.07447
- TASLP 2021(期刊)
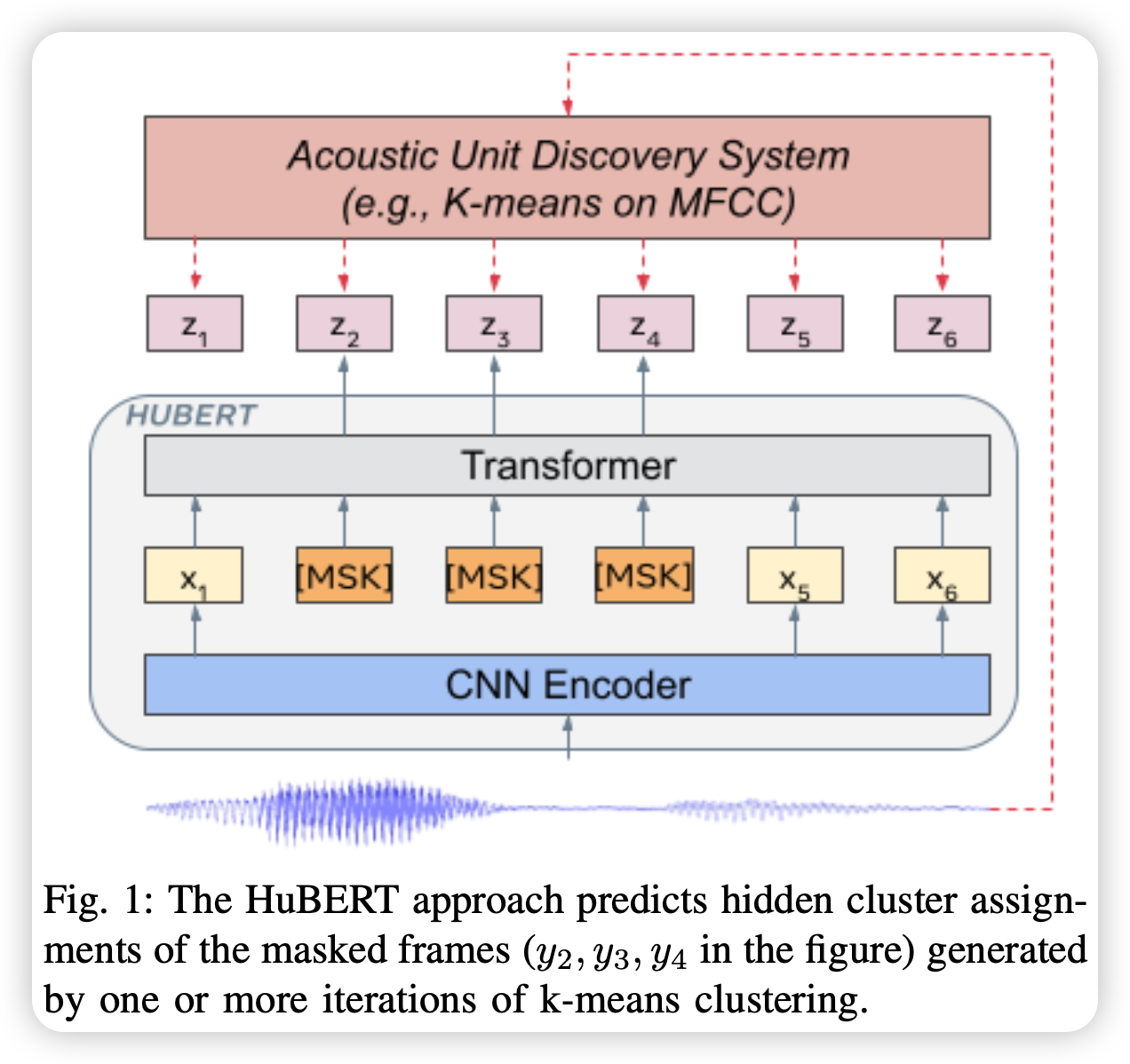 作者提到,基于自监督方法的语音表示学习主要面临三个问题:1)每条语音中有多个声音单元,2)在预训练阶段,对于输入的语音单元没有词表,3)声音单元具有可变长度,没有固定的长度。为了解决上述问题,作者提出了HuBERT,用于语音的自监督表示学习,其使用离线的聚类步骤得到了类BETR预测的对齐的标签计算loss。
总之,该模型就是利用自监督的方法得到了语音的离散表示。
作者提到,基于自监督方法的语音表示学习主要面临三个问题:1)每条语音中有多个声音单元,2)在预训练阶段,对于输入的语音单元没有词表,3)声音单元具有可变长度,没有固定的长度。为了解决上述问题,作者提出了HuBERT,用于语音的自监督表示学习,其使用离线的聚类步骤得到了类BETR预测的对齐的标签计算loss。
总之,该模型就是利用自监督的方法得到了语音的离散表示。