- 文章标题:HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
- 文章地址:https://arxiv.org/abs/2307.06949
- CVPR 2024
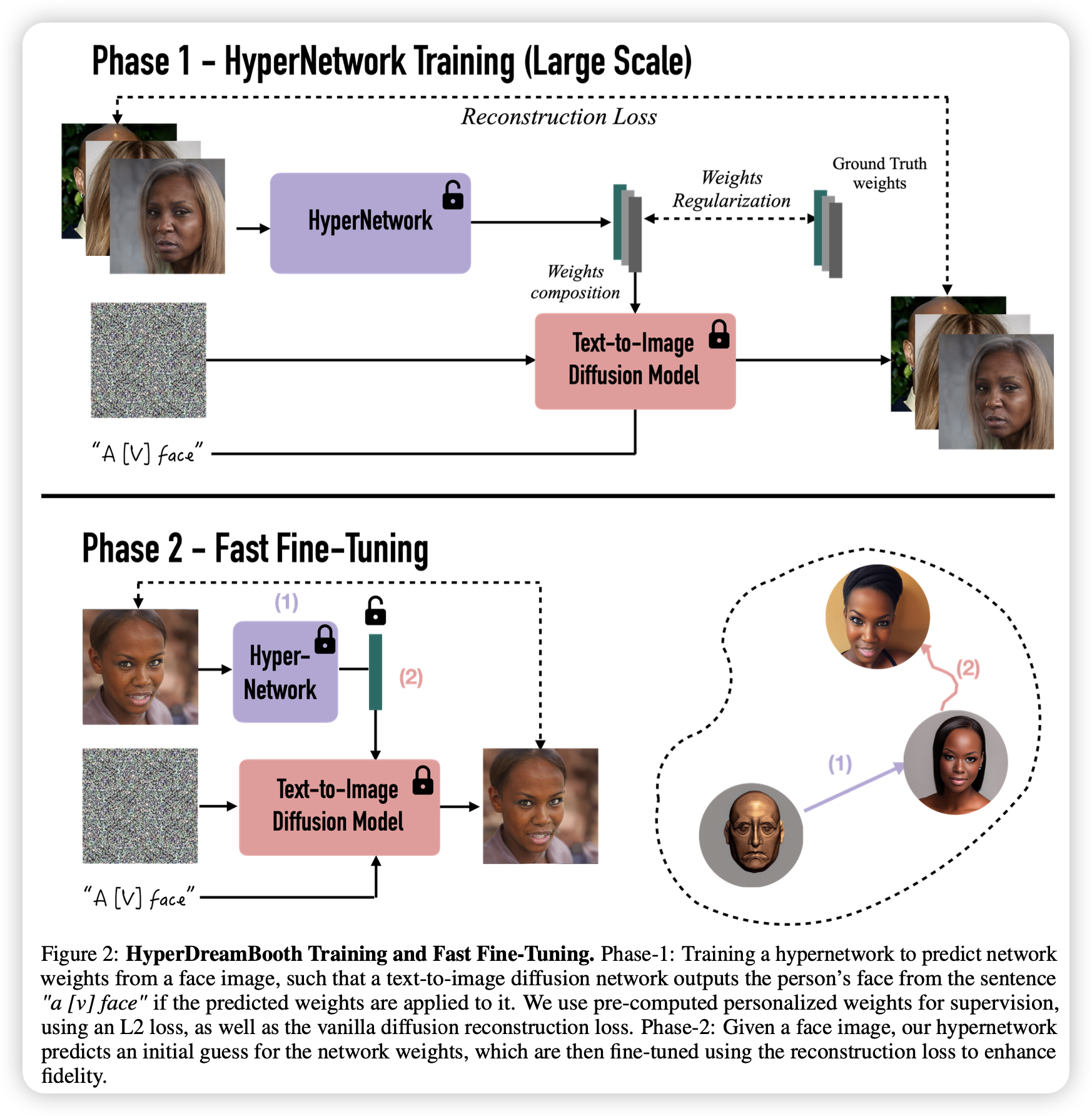 感觉跟E4T很像,都是先获得权重偏置再进行微调,作者是DreamBooth的作者。
当前定制化文生图方法存在着存储问题和算力问题,为了解决这些问题,文章提出了HyperDreamBooth,一个用于对一个张图片生成一个小的参数集合的超网络。通过结合这些参数,并进行快速微调,模型可以生成高保真的处于多种上下文和风格的特定对象的图片,同时保留模型的知识,可以仅用20s获得一张定制人脸的图片。
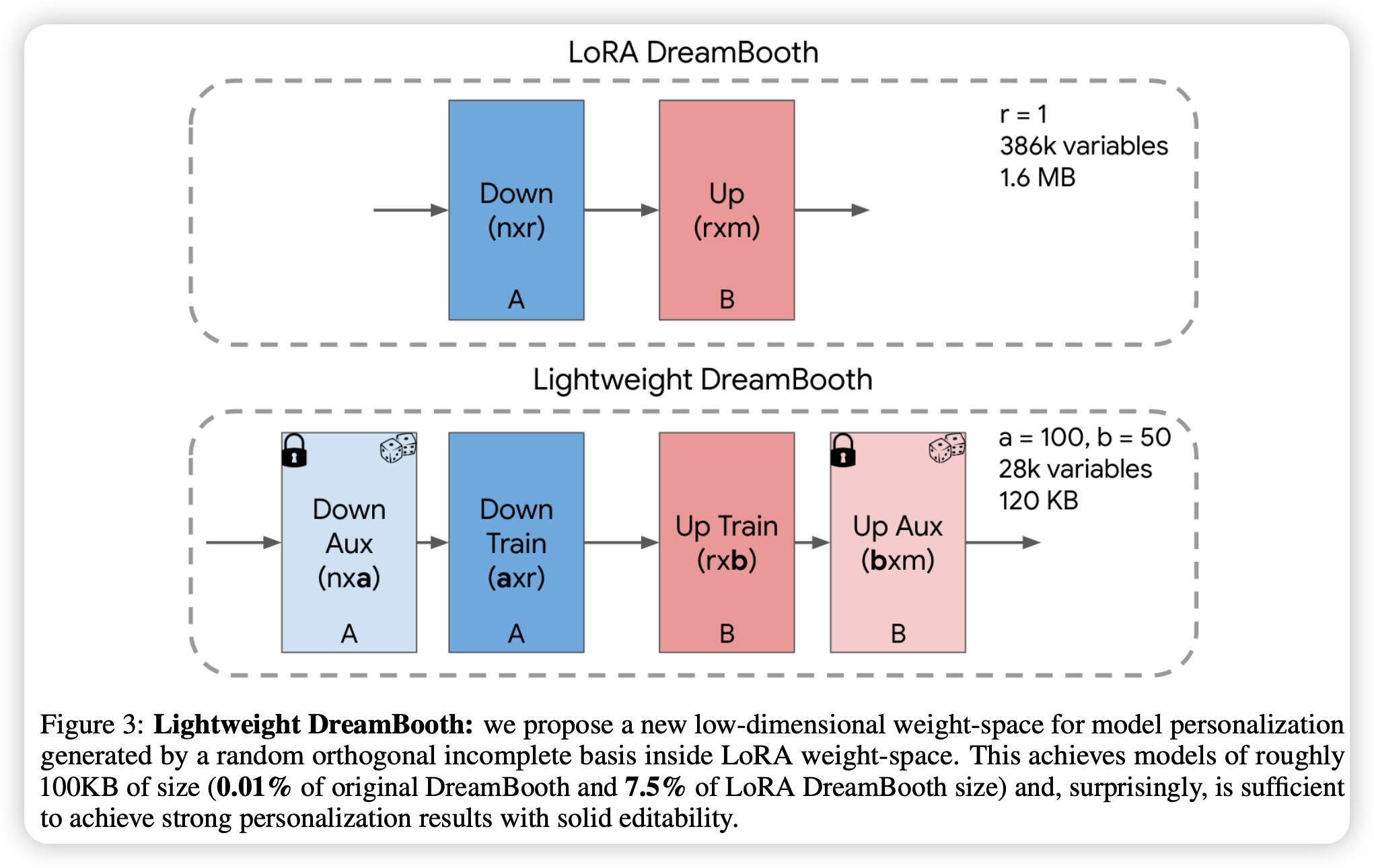
具体来说,文章首先提出了lightweight DreamBooth,一种魔改LoRA的轻量化微调方法,该模型可微调的参数非常少,因此可以更大程度保留模型知识。
感觉跟E4T很像,都是先获得权重偏置再进行微调,作者是DreamBooth的作者。
当前定制化文生图方法存在着存储问题和算力问题,为了解决这些问题,文章提出了HyperDreamBooth,一个用于对一个张图片生成一个小的参数集合的超网络。通过结合这些参数,并进行快速微调,模型可以生成高保真的处于多种上下文和风格的特定对象的图片,同时保留模型的知识,可以仅用20s获得一张定制人脸的图片。
具体来说,文章首先提出了lightweight DreamBooth,一种魔改LoRA的轻量化微调方法,该模型可微调的参数非常少,因此可以更大程度保留模型知识。
 随后利用训练好的lightweight DreamBooth的参数对超网络进行监督,训练超网络,使得提供一张人脸图片,其能够生成对应的lightweight DreamBooth参数。
随后利用训练好的lightweight DreamBooth的参数对超网络进行监督,训练超网络,使得提供一张人脸图片,其能够生成对应的lightweight DreamBooth参数。
 最后再对整个模型使用LoRA进行微调,在这个微调过程,LoRA的秩是没有限制的。从而,模型可以学到更多细节以及保证高保真度。
最后再对整个模型使用LoRA进行微调,在这个微调过程,LoRA的秩是没有限制的。从而,模型可以学到更多细节以及保证高保真度。

- 数据:CelebA-HQ
- 指标:Face Rec.(人脸识别指标);CLIP-I CLIP-T;DINO
- 硬件:未提及
- 开源:https://hyperdreambooth.github.io(未开源代码)