- 文章标题:MagiCapture: High-Resolution Multi-Concept Portrait Customization
- 文章地址:https://arxiv.org/abs/2309.06895
- AAAI 2024
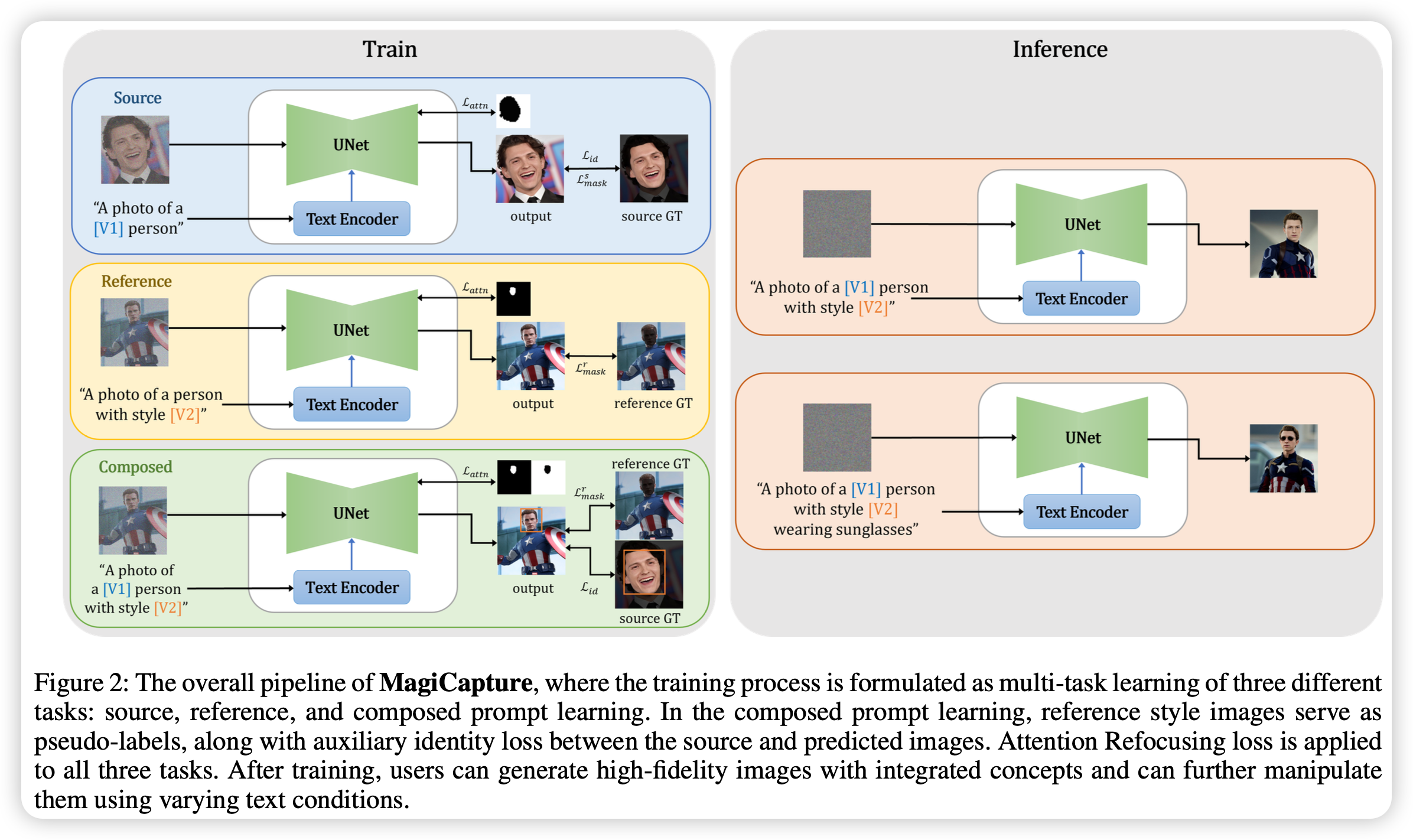 用于给定几张自拍,选定一种风格,生成特定人在某种风格的图像。
其混合提示的损失设计巧妙。
现有的定制化文生图模型的结果都不是很真实,不适合商业用途,特别是人物肖像的生成,只要有一点点不自然,人们就能捕捉到。为了解决该问题,文章提出了MagiCapture,一种只需要几张目标人物的图像和参考风格的图像就能够生成高分辨率的人物肖像。其中要解决的最大的问题是当两种概念混合在一起时生成效果不好,因为没有混合训练过,倘若要加入混合提示的训练,其缺少了GT。为了解决该问题,作者提出了一种新的注意力重新聚焦损失,加上辅助先验损失,两者都促进了这种弱监督的学习环境中的稳健学习。并且还可以使用图像的后处理进行超分辨率和人脸重建生成更清晰的图像。
具体来说,模型先对两个概念分别训练,使用lora。然后在进行混合提示训练,在这个过程中,由于缺少GT,模型将人脸和非人脸部分分开计算损失,非人脸部分将参考图像作为GT,人脸部分则将隐变量预测原图像x0,并检测人脸使用人脸识别模型提取特征,与源目标的特征计算余弦距离。
用于给定几张自拍,选定一种风格,生成特定人在某种风格的图像。
其混合提示的损失设计巧妙。
现有的定制化文生图模型的结果都不是很真实,不适合商业用途,特别是人物肖像的生成,只要有一点点不自然,人们就能捕捉到。为了解决该问题,文章提出了MagiCapture,一种只需要几张目标人物的图像和参考风格的图像就能够生成高分辨率的人物肖像。其中要解决的最大的问题是当两种概念混合在一起时生成效果不好,因为没有混合训练过,倘若要加入混合提示的训练,其缺少了GT。为了解决该问题,作者提出了一种新的注意力重新聚焦损失,加上辅助先验损失,两者都促进了这种弱监督的学习环境中的稳健学习。并且还可以使用图像的后处理进行超分辨率和人脸重建生成更清晰的图像。
具体来说,模型先对两个概念分别训练,使用lora。然后在进行混合提示训练,在这个过程中,由于缺少GT,模型将人脸和非人脸部分分开计算损失,非人脸部分将参考图像作为GT,人脸部分则将隐变量预测原图像x0,并检测人脸使用人脸识别模型提取特征,与源目标的特征计算余弦距离。

- 数据:测试时微调,测试时用了VGGFace
- 指标:人脸相似度;风格相似度(masked CLIP);美学分数;人工
- 硬件:1 RTX3090/bs1
- 开源:未开源