- 文章标题:Taming Encoder for Zero Fine-tuning Image Customization with Text-to-Image Diffusion Models
- 文章地址:https://arxiv.org/abs/2304.02642
- arxiv
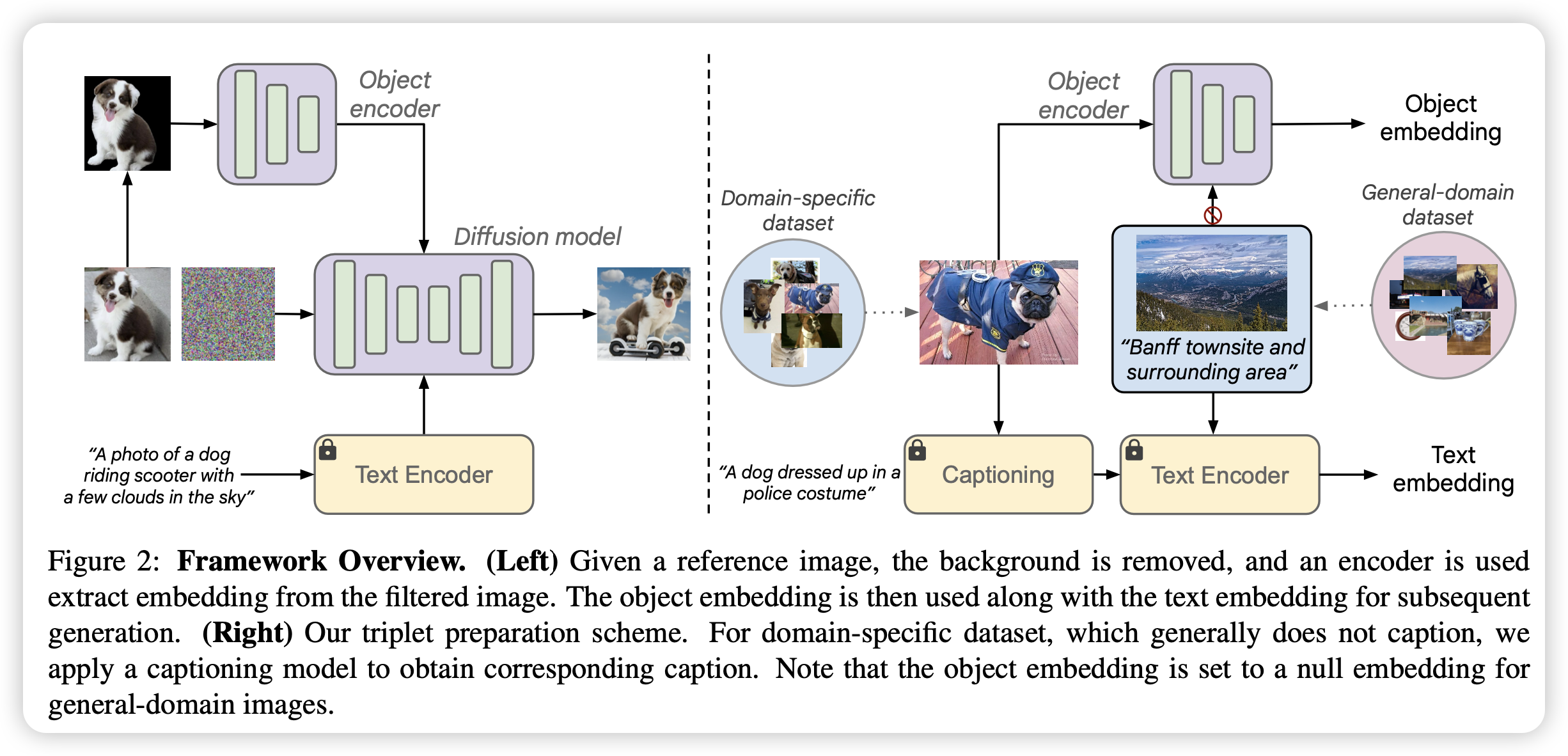 这篇文章的数据构造和正则化训练的方法值得借鉴。
文章提出了一个生成特定对象图片的方法,该方法基于通用的扩散模型架构并且避免了对每个对象都要进行冗长的优化过程。文章的架构使用了一个编码器来捕捉特定对象的高层的辨别特征,通过一个前向过程就能生成一个特定对象的embedding。
然后将该embedding给到文生图模型进行条件生成。
为了有效地将关于对象的嵌入空间与已有的文生图模型结合起来,作者尝试了不同的网络结构与训练策略,结合对象保留损失提出了一个简单但有效的正则化联合训练策略。
此外,作者还提出了一个caption生成策略,这对学习到特定对象的保持控制和编辑能力的embedding非常重要。一经训练,模型可以生成特定对象且满足文本描述的图片,且不需要测试微调。
具体来说,模型在原模型基础上进行增加,在自注意力和文本交叉注意力层中间加入了图片交叉注意力层,图片经过CLIP得到特征后输入到新增层进行特征融合。
对于数据构造,首先利用语言图像模型PaLI生成图像的caption,并使用属性分类模型生成细粒度caption,随后将两者结合起来得到最终的caption。在图像编码前,需要对背景进行mask,减少背景对特征的影响。
对于正则化联合训练,1)在特定域训练时,使用不同的参考图像和目标图像,以此来提取更鲁棒的特征。2)加入通用图像训练,通用图像不使用图像embedding。
这篇文章的数据构造和正则化训练的方法值得借鉴。
文章提出了一个生成特定对象图片的方法,该方法基于通用的扩散模型架构并且避免了对每个对象都要进行冗长的优化过程。文章的架构使用了一个编码器来捕捉特定对象的高层的辨别特征,通过一个前向过程就能生成一个特定对象的embedding。
然后将该embedding给到文生图模型进行条件生成。
为了有效地将关于对象的嵌入空间与已有的文生图模型结合起来,作者尝试了不同的网络结构与训练策略,结合对象保留损失提出了一个简单但有效的正则化联合训练策略。
此外,作者还提出了一个caption生成策略,这对学习到特定对象的保持控制和编辑能力的embedding非常重要。一经训练,模型可以生成特定对象且满足文本描述的图片,且不需要测试微调。
具体来说,模型在原模型基础上进行增加,在自注意力和文本交叉注意力层中间加入了图片交叉注意力层,图片经过CLIP得到特征后输入到新增层进行特征融合。
对于数据构造,首先利用语言图像模型PaLI生成图像的caption,并使用属性分类模型生成细粒度caption,随后将两者结合起来得到最终的caption。在图像编码前,需要对背景进行mask,减少背景对特征的影响。
对于正则化联合训练,1)在特定域训练时,使用不同的参考图像和目标图像,以此来提取更鲁棒的特征。2)加入通用图像训练,通用图像不使用图像embedding。

- 数据:人脸(CelebA);动物(LSUN-dog);内部数据
- 指标:对象相似性(CLIP);caption相似性(CLIP);KID(评估个性化输出分布与提示给出的风格有多接近)
- 硬件:64 TPUv4
- 开源:未开源