- 文章标题:When StyleGAN Meets Stable Diffusion: a W+ Adapter for Personalized Image Generation
- 文章地址:https://arxiv.org/abs/2311.17461
- CVPR 2024
 这篇文章涉及到StyleGAN的w+空间,可以学习一下这篇文章。
该方法能够在w+空间对图像进行属性的编辑(表情等)。
文本到图像扩散模型在生成多样化、高质量和逼真的图像方面非常出色。这一进步激发了人们对将特定身份纳入生成内容的兴趣日益增长。目前的大多数方法采用反转方法,使用单个参考图像将目标视觉概念嵌入文本嵌入空间。然而,新合成尺寸的面孔要么在面部属性(如表情)方面与参考图像非常相似,要么人物保真度能力降低。旨在指导合成尺寸面部的面部属性的文本描述可能会失效,因为身份信息与来自参考图像的与身份无关的面部属性错综复杂耦合在一起。为了解决这些问题,我们提出了扩展的StyleGAN嵌入空间W+的新颖使用,以实现扩散模型的增强身份保留和解耦。通过将这种语义上有意义的人脸隐空间与文本到图像扩散模型对齐,我们成功地在id方面保持了高保真度,并结合了语义编辑的能力。此外,我们提出了新的训练目标,以平衡提示和身份条件的影响,确保在面部属性修改期间与身份无关的背景不受影响。广泛的实验表明,我们的方法可以熟練地生成个性化的文本到图像输出,这些输出不仅与提示描述兼容,而且还可以适应各种设置中常见的StyleGAN编辑方向。
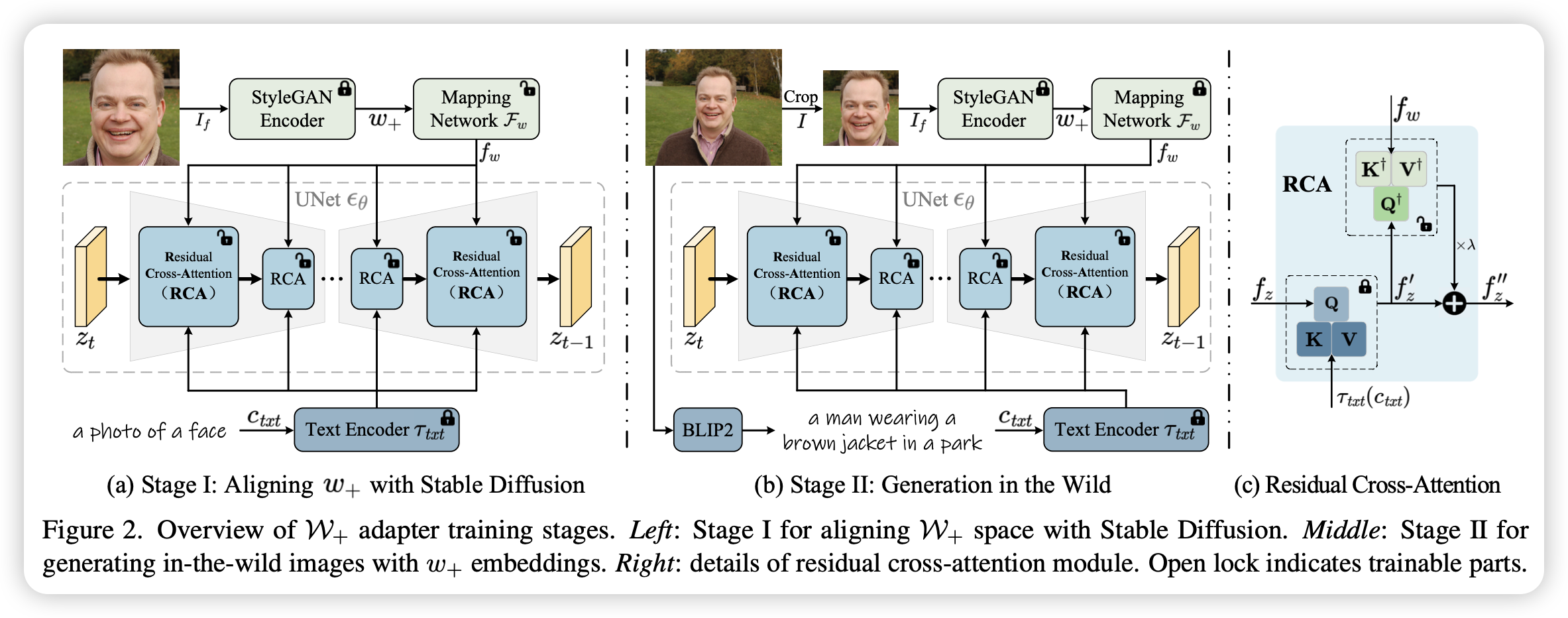
具体来说,训练分为两个阶段。第一个阶段训练映射网络将w+空间映射到扩散模型的条件空间,并且将该条件通过一个增加的交叉注意力模块引导图像的生成,具体结构见主图,在该阶段训练的数据由人脸框图片(不是整张图像)加对应的w+ embedding组成。第二个阶段目的是为了提高模型在更广泛的场景下的表现能力,这个阶段只训练增加的交叉注意力模块,训练数据由原图像及其caption组成,w+ embbeding由裁剪的人脸得到。
这篇文章涉及到StyleGAN的w+空间,可以学习一下这篇文章。
该方法能够在w+空间对图像进行属性的编辑(表情等)。
文本到图像扩散模型在生成多样化、高质量和逼真的图像方面非常出色。这一进步激发了人们对将特定身份纳入生成内容的兴趣日益增长。目前的大多数方法采用反转方法,使用单个参考图像将目标视觉概念嵌入文本嵌入空间。然而,新合成尺寸的面孔要么在面部属性(如表情)方面与参考图像非常相似,要么人物保真度能力降低。旨在指导合成尺寸面部的面部属性的文本描述可能会失效,因为身份信息与来自参考图像的与身份无关的面部属性错综复杂耦合在一起。为了解决这些问题,我们提出了扩展的StyleGAN嵌入空间W+的新颖使用,以实现扩散模型的增强身份保留和解耦。通过将这种语义上有意义的人脸隐空间与文本到图像扩散模型对齐,我们成功地在id方面保持了高保真度,并结合了语义编辑的能力。此外,我们提出了新的训练目标,以平衡提示和身份条件的影响,确保在面部属性修改期间与身份无关的背景不受影响。广泛的实验表明,我们的方法可以熟練地生成个性化的文本到图像输出,这些输出不仅与提示描述兼容,而且还可以适应各种设置中常见的StyleGAN编辑方向。
具体来说,训练分为两个阶段。第一个阶段训练映射网络将w+空间映射到扩散模型的条件空间,并且将该条件通过一个增加的交叉注意力模块引导图像的生成,具体结构见主图,在该阶段训练的数据由人脸框图片(不是整张图像)加对应的w+ embedding组成。第二个阶段目的是为了提高模型在更广泛的场景下的表现能力,这个阶段只训练增加的交叉注意力模块,训练数据由原图像及其caption组成,w+ embbeding由裁剪的人脸得到。

- 数据:FFHQ(人脸)+利用StyleGAN2生成的图片+SHHQ(人的全身)
- 指标:CLIP;ID相似度(arcface)
- 硬件:8 V100/bs16
- 开源:https://github.com/csxmli2016/w-plus-adapter