- 文章标题:Break-A-Scene: Extracting Multiple Concepts from a Single Image
- 文章地址:https://arxiv.org/abs/2305.16311
- SIGGRAPH Asia 2023
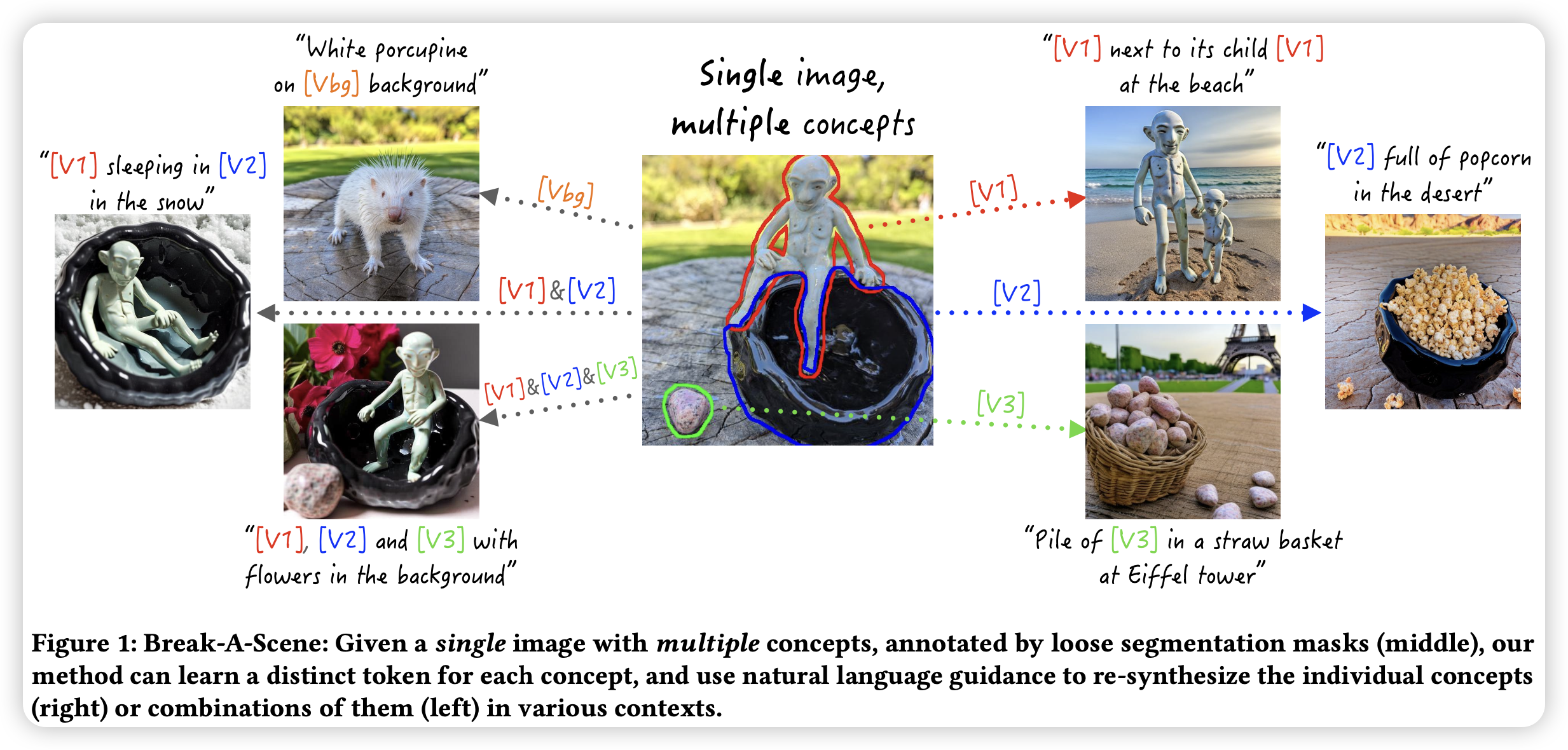
 当前的定制化文生图的方法专注于从多个图片中学习一个对象。文章提出了一个新的任务,即文本场景分离:给定一张图片(包含多个对象),目标为提取每个对象对应的特定的token,在生成的过程中能够完成细粒度控制。为了完成该任务,文章得到该图像的多个对象对应的mask,指定对应的对象。mask由用户或者分割模型得到。然后作者提出了新的两阶段的定制化方法,首先优化特定对象的embedding,然后将模型参数与embedding一块训练。
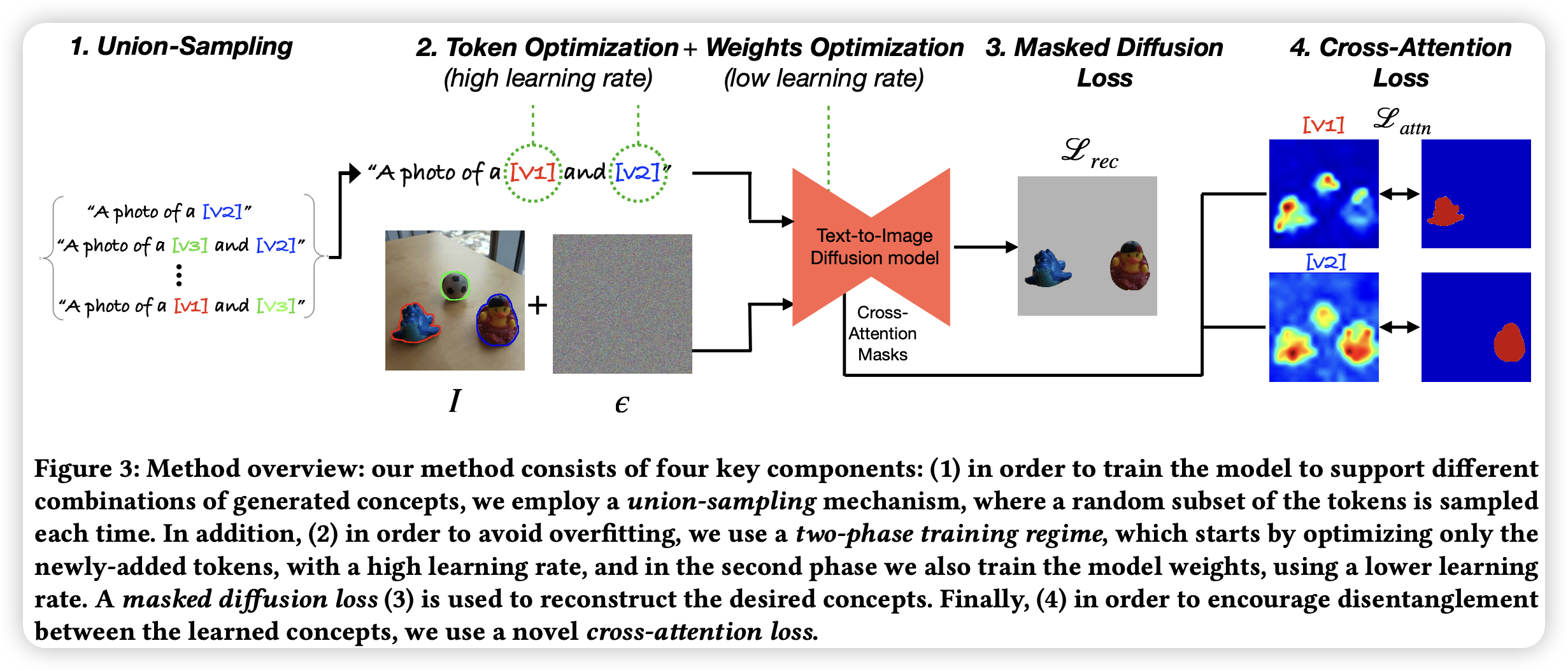
作者使用了mask diffusion loss使token能够捕捉到特定的对象,并且使用了在cross-attention maps上的loss用于解耦不同的对象。同样在训练时,作者提出了union-sampling,一个训练策略用于增强联合多个对象生成图片的能力(即训练时随机混合N个对象进行训练)。
最后文章指出了不足,1)模型不能解耦光照条件与对象,2)模型不能解耦姿势与对象,3)超过4个对象表现不佳,4)计算的参数量大。
当前的定制化文生图的方法专注于从多个图片中学习一个对象。文章提出了一个新的任务,即文本场景分离:给定一张图片(包含多个对象),目标为提取每个对象对应的特定的token,在生成的过程中能够完成细粒度控制。为了完成该任务,文章得到该图像的多个对象对应的mask,指定对应的对象。mask由用户或者分割模型得到。然后作者提出了新的两阶段的定制化方法,首先优化特定对象的embedding,然后将模型参数与embedding一块训练。
作者使用了mask diffusion loss使token能够捕捉到特定的对象,并且使用了在cross-attention maps上的loss用于解耦不同的对象。同样在训练时,作者提出了union-sampling,一个训练策略用于增强联合多个对象生成图片的能力(即训练时随机混合N个对象进行训练)。
最后文章指出了不足,1)模型不能解耦光照条件与对象,2)模型不能解耦姿势与对象,3)超过4个对象表现不佳,4)计算的参数量大。
- 数据:test-tuning
- 指标:prompt similarity(CLIP);ID preservation DINO(借鉴DreamBooth)
- 硬件:未指出
- 开源:https://github.com/google/break-a-scene