- 文章标题:Prompt-to-Prompt Image Editing with Cross Attention Control
- 文章地址:https://arxiv.org/abs/2208.01626
- ICLR 2023
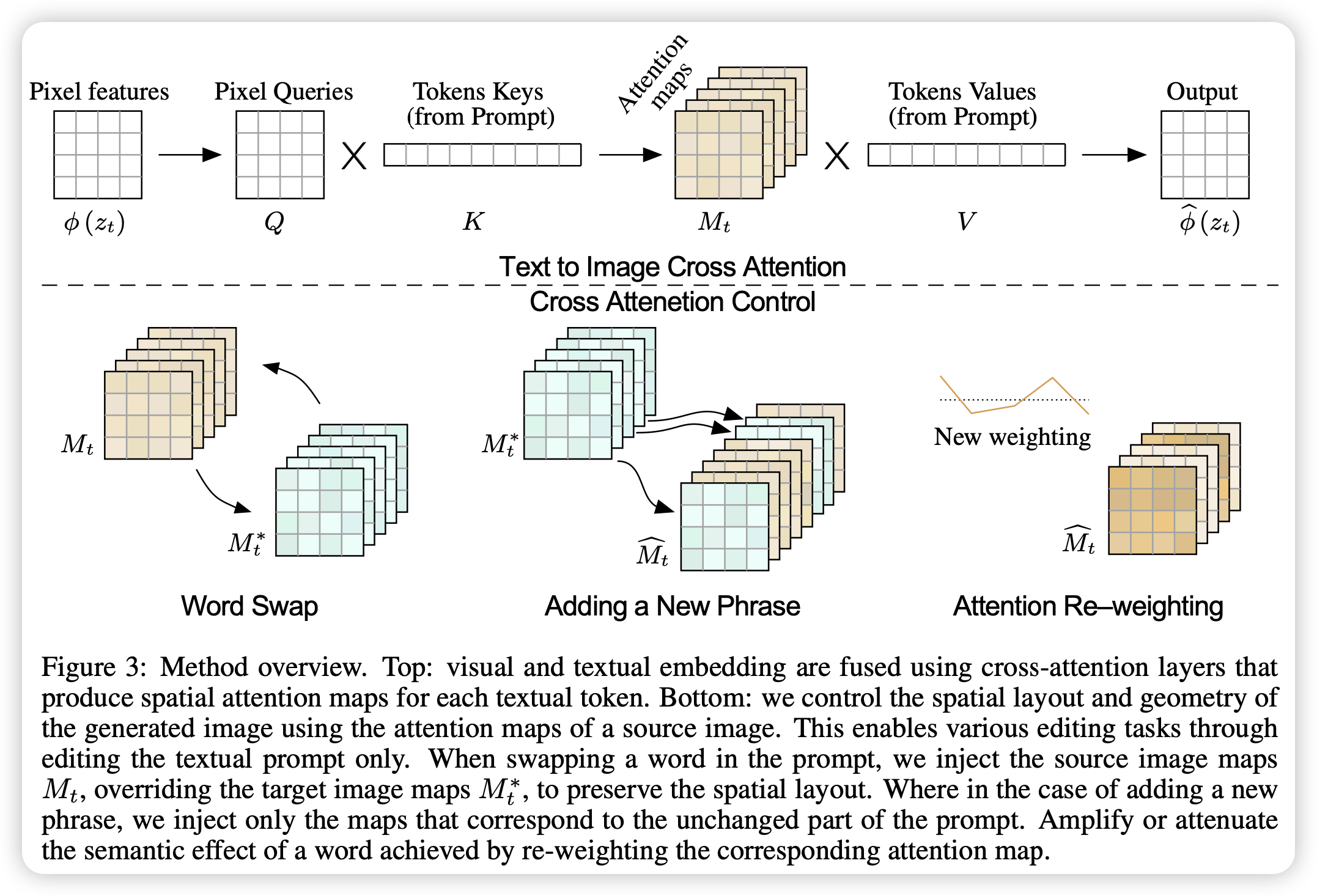 文生图最近得到了迅速发展和广泛的关注,文章很自然的想到了将文生图模型扩展到图像编辑上。编辑对于生成模型来说是具有挑战性的,因为图像编辑的特点就是保持图片其他部分不变,而文生图模型在微弱改变文本后会产生完全不一样的输出。之前有工作利用mask来限制生成过程,本文章提出了一个Prompt-to-Prompt的图像编辑框架,可以实现只通过文本对图像进行编辑。
为了完成该目标,作者深入分析了文生图模型,并且发现交叉注意力层是控制图像布局和每个单词之间联系的关键。基于此发现,可以实现词替换、增加约束和控制某个单词的影响程度的图像编辑应用。
文生图最近得到了迅速发展和广泛的关注,文章很自然的想到了将文生图模型扩展到图像编辑上。编辑对于生成模型来说是具有挑战性的,因为图像编辑的特点就是保持图片其他部分不变,而文生图模型在微弱改变文本后会产生完全不一样的输出。之前有工作利用mask来限制生成过程,本文章提出了一个Prompt-to-Prompt的图像编辑框架,可以实现只通过文本对图像进行编辑。
为了完成该目标,作者深入分析了文生图模型,并且发现交叉注意力层是控制图像布局和每个单词之间联系的关键。基于此发现,可以实现词替换、增加约束和控制某个单词的影响程度的图像编辑应用。
