- 文章标题:ELITE: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation
- 文章地址:https://arxiv.org/abs/2302.13848
- ICCV 2023
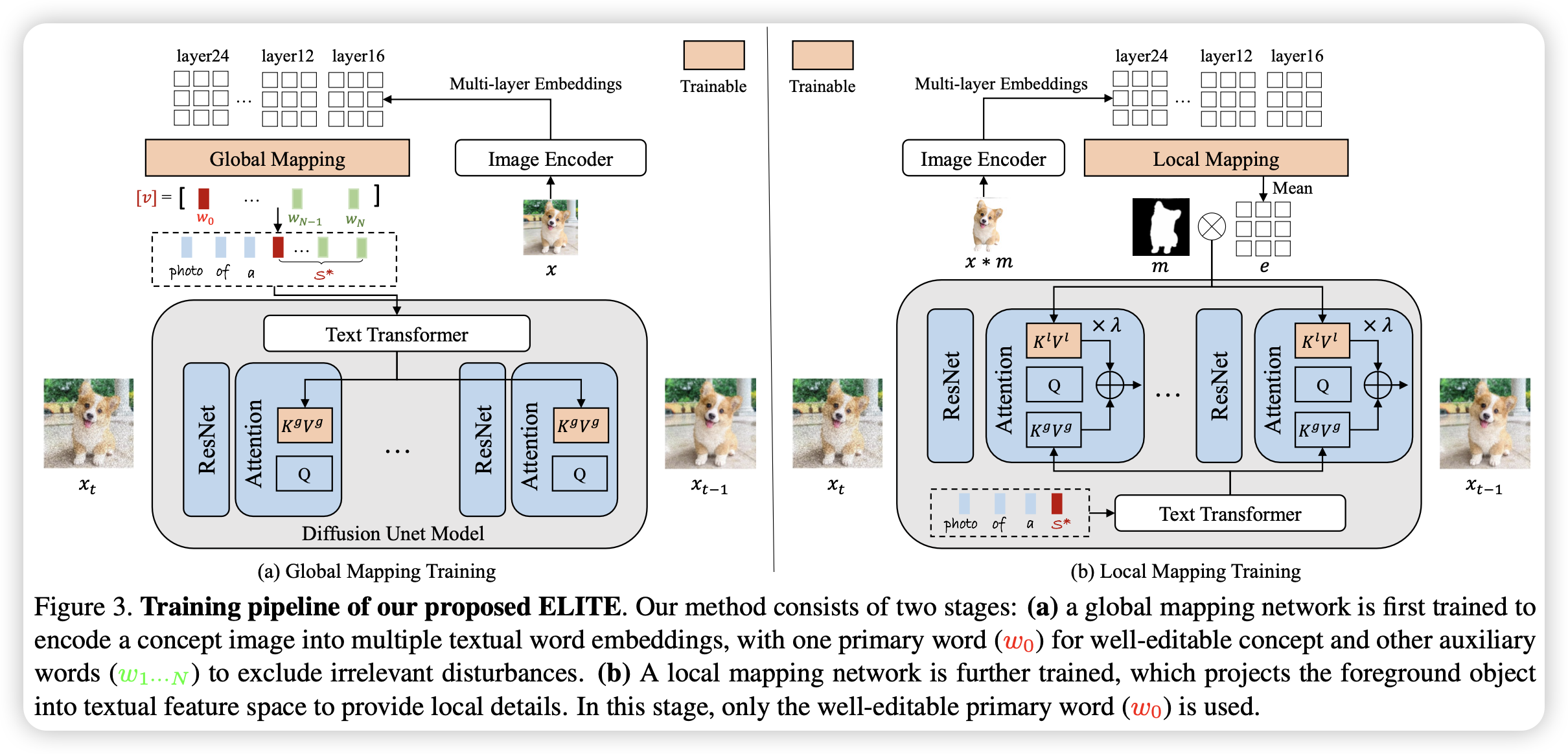 当前定制对象的文生图一般都是基于优化的方法,这带来了过多的计算和存储困难。文章提出了ELITE,一个由全局映射网络和局部映射网络组成的基于学习的编码器,用于快速和准确的个性化文生图。
具体来说,全局映射网络将图像的多层特征(CLIP Image Encoder)映射到文本单词的嵌入空间中的多个新的词中,其中包含一个最主要的包含可编辑的主要概念的词和一些用于去除目标概念无关信息的副助词。局部映射网络将编码后的局部特征注入到交叉注意力层,以此提供目标概念的补充细节同时保留了可编辑性。
文章通过实验证明了网络结构的有效性和合理性,同时指出了在生成包含文字的图片的不足。
当前定制对象的文生图一般都是基于优化的方法,这带来了过多的计算和存储困难。文章提出了ELITE,一个由全局映射网络和局部映射网络组成的基于学习的编码器,用于快速和准确的个性化文生图。
具体来说,全局映射网络将图像的多层特征(CLIP Image Encoder)映射到文本单词的嵌入空间中的多个新的词中,其中包含一个最主要的包含可编辑的主要概念的词和一些用于去除目标概念无关信息的副助词。局部映射网络将编码后的局部特征注入到交叉注意力层,以此提供目标概念的补充细节同时保留了可编辑性。
文章通过实验证明了网络结构的有效性和合理性,同时指出了在生成包含文字的图片的不足。

- 数据:OpenImage
- 指标:CLIP-I CLIP-T DINO-I 推理时间
- 硬件:4 V100/bs16
- 开源: