- 文章标题:Multi-Concept Customization of Text-to-Image Diffusion
- 文章地址:https://arxiv.org/abs/2212.04488
- CVPR 2023
 当前的文生图模型可以生成高质量的图像,我们可以让模型根据给定的图像去生成该对象的不同上下文的图片吗?更进一步,可以在一张图中生成多个特定对象吗?文章提出了Custom Diffusion,一个高效的增强现有文生图模型的方法。
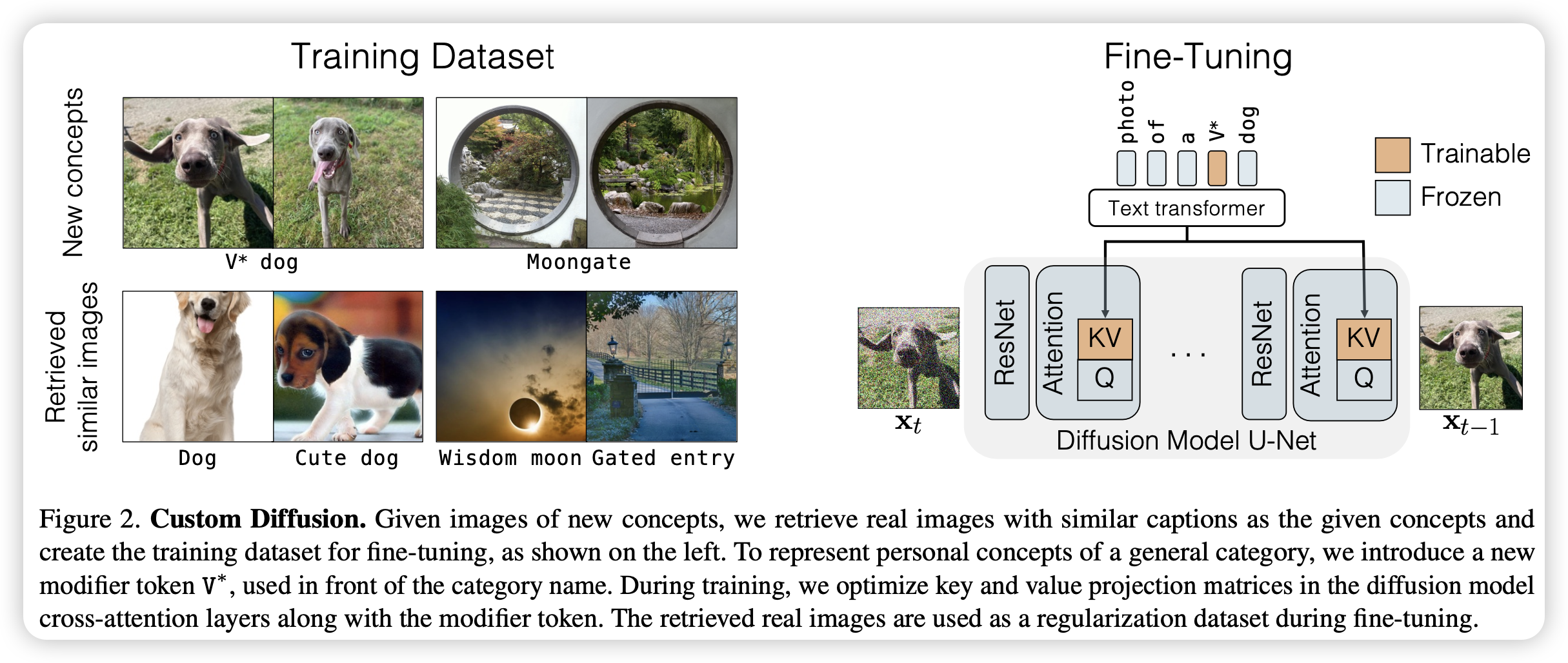
文章提出只需训练少部分参数(cross-attention中的KV矩阵)即可使模型具有生成特定对象的能力。对于多对象生成,模型可以共同训练多个特定对象,或者联合多个微调后的模型。
对于单个对象的微调,模型仅微调cross-attention中的KV矩阵,使用特定的token指定该对象(这个token的embedding也随着微调而训练),并且为了避免过拟合,模型在真实数据集中检索相近语义(CLIP分数相近)的caption的图片共同微调模型。
文章通过大量实验证明了方法的有效性,并且证明了防止过拟合的效果(KID)。最后指出了不足,模型继承了原模型在生成相近对象在同一场景下的能力缺陷,并且在三个以上的对象生成中表现不佳。
当前的文生图模型可以生成高质量的图像,我们可以让模型根据给定的图像去生成该对象的不同上下文的图片吗?更进一步,可以在一张图中生成多个特定对象吗?文章提出了Custom Diffusion,一个高效的增强现有文生图模型的方法。
文章提出只需训练少部分参数(cross-attention中的KV矩阵)即可使模型具有生成特定对象的能力。对于多对象生成,模型可以共同训练多个特定对象,或者联合多个微调后的模型。
对于单个对象的微调,模型仅微调cross-attention中的KV矩阵,使用特定的token指定该对象(这个token的embedding也随着微调而训练),并且为了避免过拟合,模型在真实数据集中检索相近语义(CLIP分数相近)的caption的图片共同微调模型。
文章通过大量实验证明了方法的有效性,并且证明了防止过拟合的效果(KID)。最后指出了不足,模型继承了原模型在生成相近对象在同一场景下的能力缺陷,并且在三个以上的对象生成中表现不佳。
