- 文章标题:FastComposer: Tuning-Free Multi-Subject Image Generation with Localized Attention
- 文章地址:https://arxiv.org/abs/2305.10431
- IJCV 2024
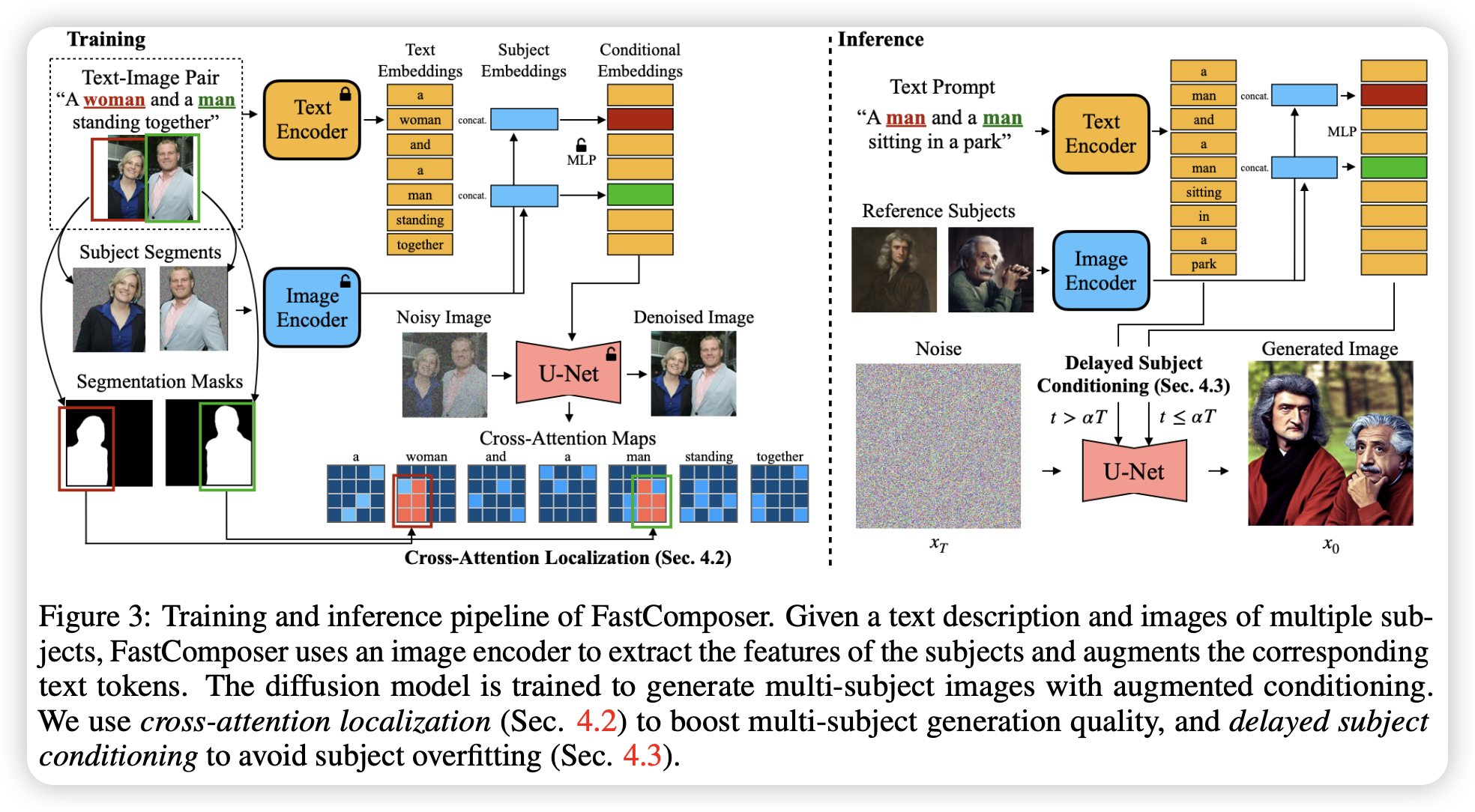 当前对象驱动的定制文生图模型大都因为需要微调而低效,此外,现有方法难以实现多主体生成,因为它们通常会混合主体间的身份。文章提出了FastComposer,无需微调的高效、定制化、多目标文生图模型。其使用图像编码器获取对象的embedding从而增强原本的文本条件,实现了基于特定对象的图片和文本指令的定制化图像生成。
为了解决多主体生成中的身份混合问题,FastComposer在训练中使用了交叉注意力位置监督,使参考主体的注意力集中在正确的位置上。简单地将主体embedding作为条件引导生成会导致过拟合,FastComposer提出了延缓主体条件生成的方法,将去噪的步骤分成两部分,第一部分先使用纯文本引导,第二部分使用主体进行引导。这样保证了主体一致性和可编辑性。
当前对象驱动的定制文生图模型大都因为需要微调而低效,此外,现有方法难以实现多主体生成,因为它们通常会混合主体间的身份。文章提出了FastComposer,无需微调的高效、定制化、多目标文生图模型。其使用图像编码器获取对象的embedding从而增强原本的文本条件,实现了基于特定对象的图片和文本指令的定制化图像生成。
为了解决多主体生成中的身份混合问题,FastComposer在训练中使用了交叉注意力位置监督,使参考主体的注意力集中在正确的位置上。简单地将主体embedding作为条件引导生成会导致过拟合,FastComposer提出了延缓主体条件生成的方法,将去噪的步骤分成两部分,第一部分先使用纯文本引导,第二部分使用主体进行引导。这样保证了主体一致性和可编辑性。

- 数据:基于FFHQ-wild(人脸数据集)建造的数据
- 指标:ID-preservation(检测人脸后使用FaceNet计算相似度,对于多目标,使用贪心匹配计算相似度);Prompt Consistency(使用CLIP Score);Total Time(微调和推理所消耗的时间);最大内存占用。
- 硬件:8 A6000/bs128
- 开源:https://github.com/mit-han-lab/fastcomposer