- 文章标题:SVDiff: Compact Parameter Space for Diffusion Fine-Tuning
- 文章地址:https://arxiv.org/abs/2303.11305
- ICCV 2023
 扩散模型在文生图任务上取得了高速发展,然而现有的定制化输出的方法存在一些限制,如捕捉多对象,过拟合风险以及需要微调的参数量。
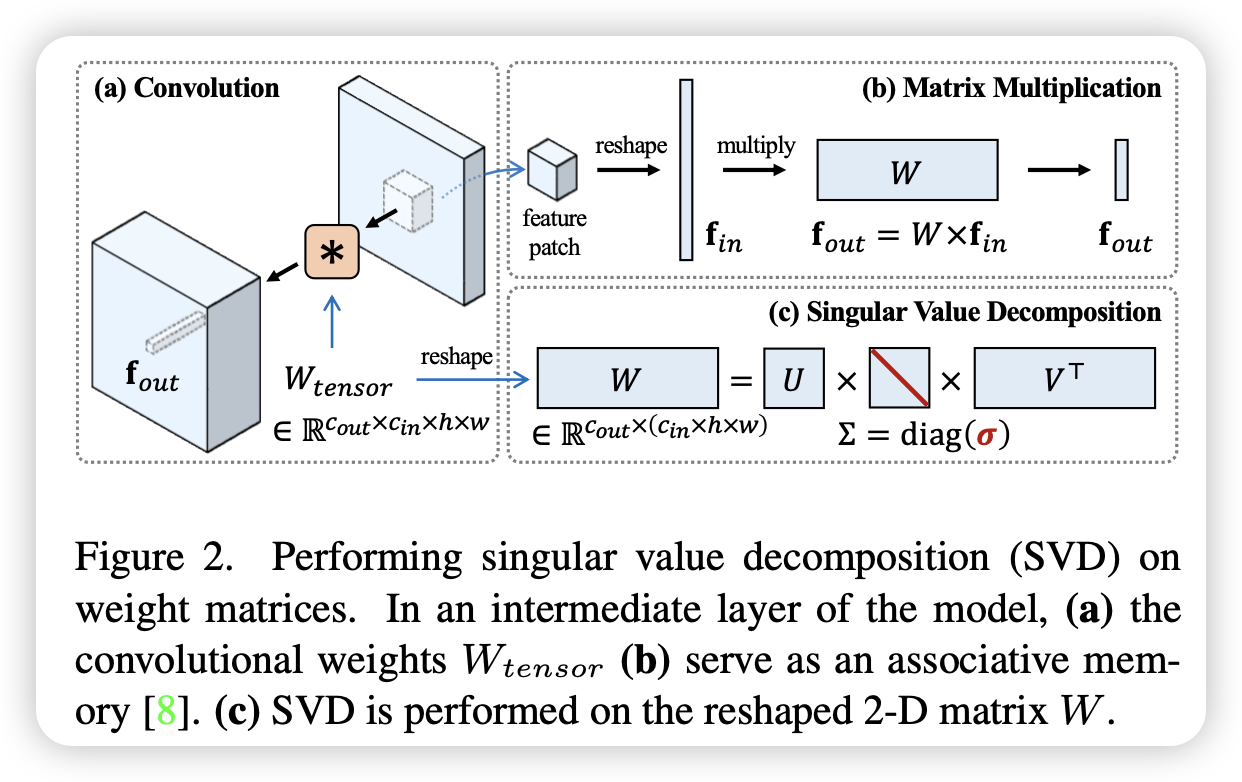
文章提出了新的方法来解决这些定制化文生图模型中存在的问题,包含对权重矩阵的奇异值进行微调从而得到一个高效的参数空间减少了过拟合的风险。
此外文章还提出了一个Cut-Mix-Unmix数据增强的方法来增强多对象图像生成的质量和一个简单的基于文本的图像编辑架构。
文章提出的SVDiff方法相对于现有方法具有非常小的模型大小(比常规的DreamBooth小2200倍)。
扩散模型在文生图任务上取得了高速发展,然而现有的定制化输出的方法存在一些限制,如捕捉多对象,过拟合风险以及需要微调的参数量。
文章提出了新的方法来解决这些定制化文生图模型中存在的问题,包含对权重矩阵的奇异值进行微调从而得到一个高效的参数空间减少了过拟合的风险。
此外文章还提出了一个Cut-Mix-Unmix数据增强的方法来增强多对象图像生成的质量和一个简单的基于文本的图像编辑架构。
文章提出的SVDiff方法相对于现有方法具有非常小的模型大小(比常规的DreamBooth小2200倍)。
