- 文章标题:IDAdapter: Learning Mixed Features for Tuning-Free Personalization of Text-to-Image Models
- 文章地址:https://arxiv.org/abs/2403.13535
- CVPRW 2024
 当前定制化文生图模型面临一些挑战,包括测试微调,多图片输入,id保留度不足以及多样化不足的输出。为了解决这些问题,文章提出了IDAdapter,一种免测试微调的增强多样性以及id保留度的单一人脸图像输入的方法。
IDAdapter通过结合文本和视觉注入以及一个人脸损失将一个特定人脸与生成过程结合起来。在训练过程,模型采用来自同一个id的多张参考图片的混合特征来增强id相关的细节信息,使得模型生成更加多样化风格、情感以及角度的图像。
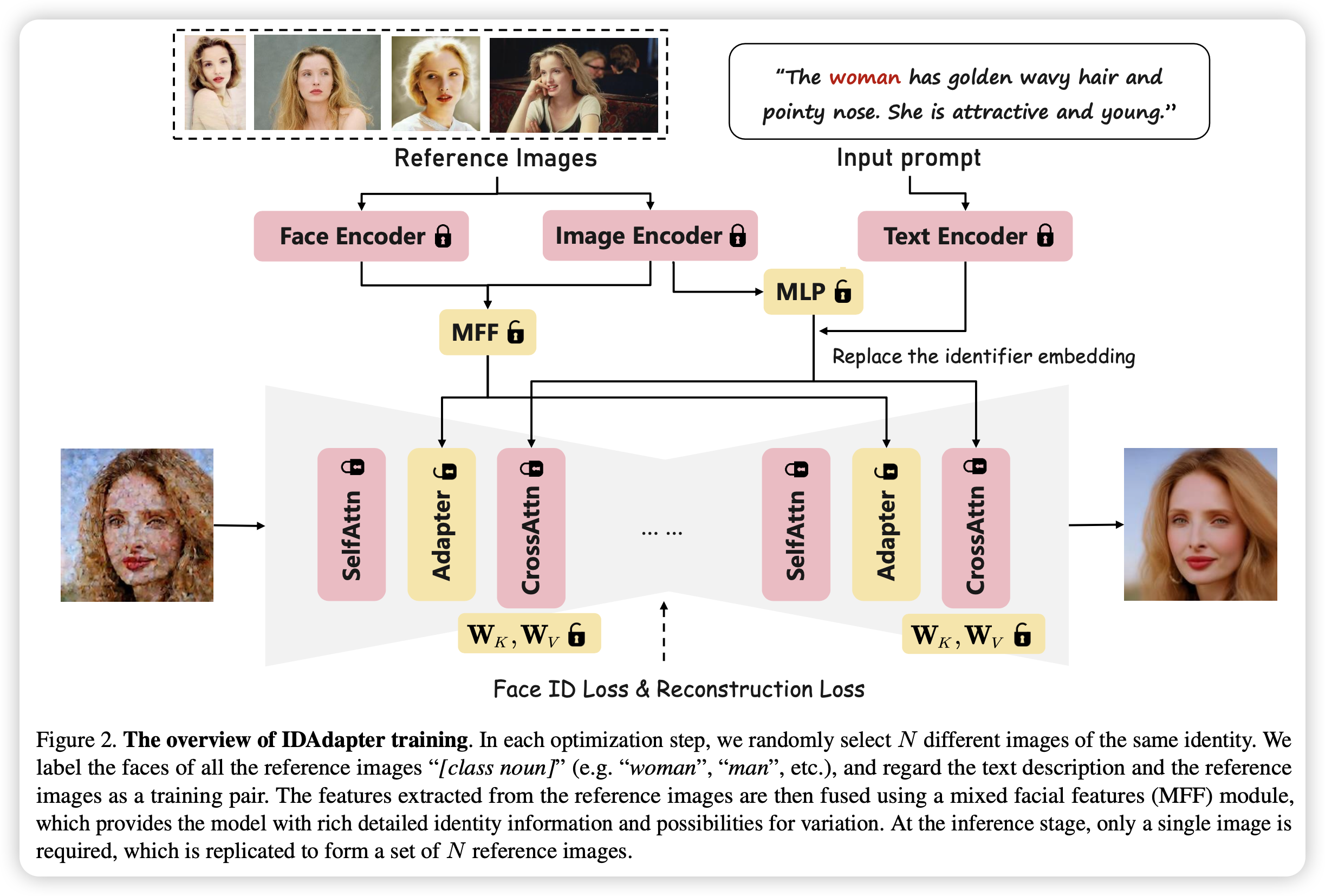
具体来说,在训练时,模型使用人脸识别模型和CLIP分别得到图像的两类特征,然后使用MFF模块混合特征,输入到Adapter,以此注入图像的细节特征。对于文本部分,模型使用CLIP的类别特征,并将其替换特定标识符,以此将该目标嵌入到文本空间。并且除了标准扩散模型损失外,文章还使用了人脸损失,进一步提高了人脸的一致性。
当前定制化文生图模型面临一些挑战,包括测试微调,多图片输入,id保留度不足以及多样化不足的输出。为了解决这些问题,文章提出了IDAdapter,一种免测试微调的增强多样性以及id保留度的单一人脸图像输入的方法。
IDAdapter通过结合文本和视觉注入以及一个人脸损失将一个特定人脸与生成过程结合起来。在训练过程,模型采用来自同一个id的多张参考图片的混合特征来增强id相关的细节信息,使得模型生成更加多样化风格、情感以及角度的图像。
具体来说,在训练时,模型使用人脸识别模型和CLIP分别得到图像的两类特征,然后使用MFF模块混合特征,输入到Adapter,以此注入图像的细节特征。对于文本部分,模型使用CLIP的类别特征,并将其替换特定标识符,以此将该目标嵌入到文本空间。并且除了标准扩散模型损失外,文章还使用了人脸损失,进一步提高了人脸的一致性。

- 数据:CelebA-HQ(为了得到同一id的多张图片,还使用了包含换脸(InsightFace)的多种数据增强方法)
- 指标:ID相似度(使用人脸识别模型计算特征的余弦距离);姿势多样性(角度多样性:俯仰角和偏航角);情感多样性(使用情感分类模型计算生成和原本数据的不同表情的比例)
- 硬件:1 A100/bs4
- 开源:未开源