- 文章标题:Unified Multi-Modal Latent Diffusion for Joint Subject and Text Conditional Image Generation
- 文章地址:https://arxiv.org/abs/2303.09319
- arxiv
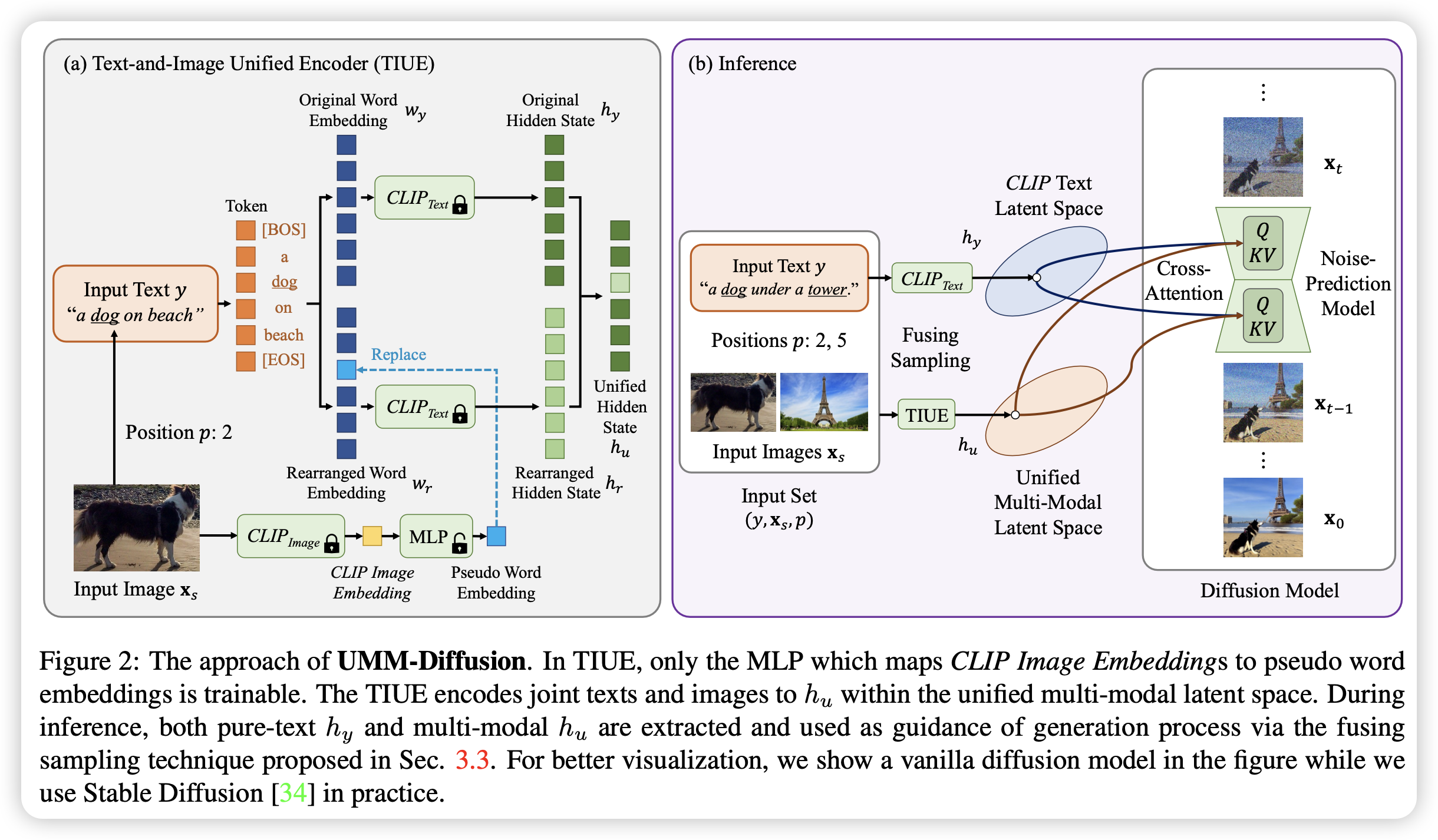 当前语言引导的图片生成使用扩散模型得到了很好的发展,然而对于特定对象的生成,文字没办法做到足够细致。在这篇文章,作者提出了UMM-Diffusion,可以实现同时将文字与图片作为生成条件从而生成特定对象的图片。
具体来说,文字与图片都经过编码器编码到同一个多模态的隐空间,在这里,输入的图片经过学习映射到伪词embedding,并与文本共同引导生成过程。首先将输入图像经过CLIP得到特征,之后使用MLP映射到伪词embedding中并嵌入到文本embedding的指定位置,随后经过CLIP得到混合特征,并且为了进一步防止过拟合,使用纯文本的特征并将指定位置替换为混合特征,这样就得到了图片+文本的混合引导条件。
另外,为了消除图片中无关对象的部分(背景、光照等)的影响,作者还提出了一种新的采样方法,将多模态的引导结果与纯文本的引导结果混合起来,即制定一个配比,混合两种引导条件。1
当前语言引导的图片生成使用扩散模型得到了很好的发展,然而对于特定对象的生成,文字没办法做到足够细致。在这篇文章,作者提出了UMM-Diffusion,可以实现同时将文字与图片作为生成条件从而生成特定对象的图片。
具体来说,文字与图片都经过编码器编码到同一个多模态的隐空间,在这里,输入的图片经过学习映射到伪词embedding,并与文本共同引导生成过程。首先将输入图像经过CLIP得到特征,之后使用MLP映射到伪词embedding中并嵌入到文本embedding的指定位置,随后经过CLIP得到混合特征,并且为了进一步防止过拟合,使用纯文本的特征并将指定位置替换为混合特征,这样就得到了图片+文本的混合引导条件。
另外,为了消除图片中无关对象的部分(背景、光照等)的影响,作者还提出了一种新的采样方法,将多模态的引导结果与纯文本的引导结果混合起来,即制定一个配比,混合两种引导条件。1

- 数据:LAION-400M
- 指标:时间成本(该方法无需测试微调)
- 硬件:32 V100/bs192
- 开源:未开源