- 文章标题:RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR
- 文章地址:https://arxiv.org/abs/2209.14491
- ICLR 2023
 当前文生图对常见的对象生成效果很好,但对于一些不常见的对象,如Chortai (一种狗)和Picarones (一种食物),其生成内容就不能保证了。为了解决该问题,作者提出了Re-Imagen,一个利用检索信息使文生图效果更好的模型,特别是对于罕见或模型从未见过的对象。
给定一个文本prompt,Re-Imagen通过访问外部知识库(图文对)检索相关的内容,然后将该内容作为参考生成图像。通过该过程,Re-Imagen由于高层的语义信息和低层的视觉细节信息对生成过程进行了增强。此外,为了平衡文本对齐和检索内容的对齐,作者利用了一种新的采样策略去混合文本条件和检索条件的classifier-free guidance。
最后为了更全面地评测模型的能力,作者提出了EntityDrawBench,一个新的基准用于评价多种对象的图像生成能力,从常见到罕见。
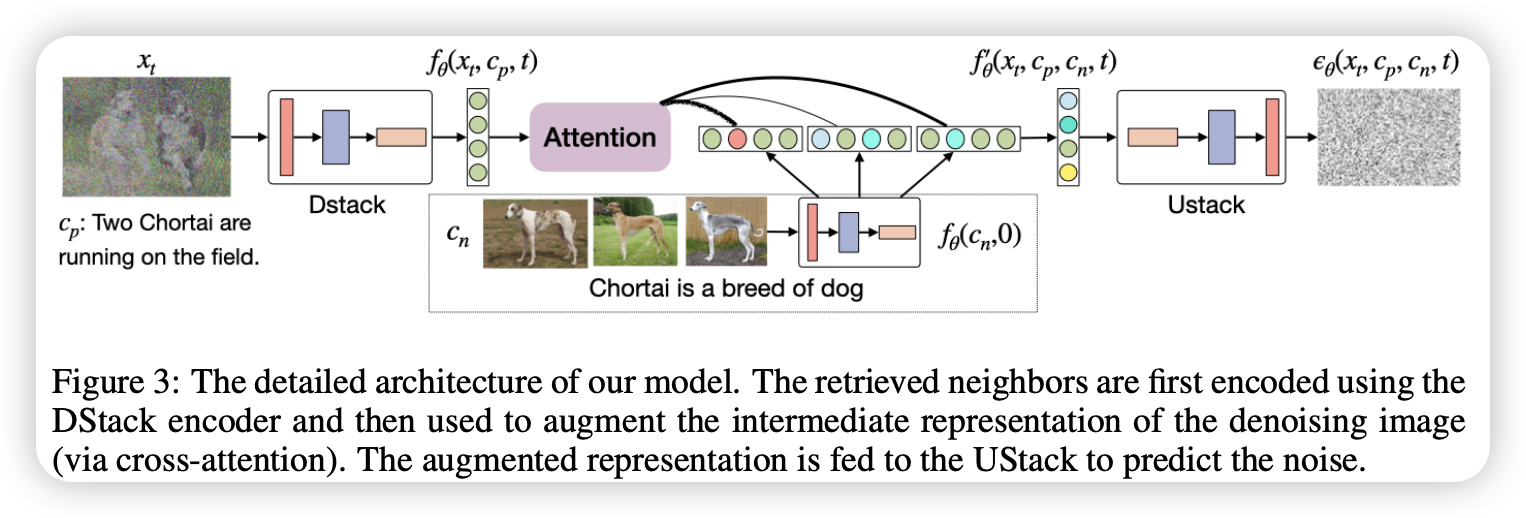
具体来说,Re-Imagen将检索到的内容经过同样的Unet的编码阶段得到特征,然后与原特征进行cross-attention操作,从而将检索的信息融合进模型。
当前文生图对常见的对象生成效果很好,但对于一些不常见的对象,如Chortai (一种狗)和Picarones (一种食物),其生成内容就不能保证了。为了解决该问题,作者提出了Re-Imagen,一个利用检索信息使文生图效果更好的模型,特别是对于罕见或模型从未见过的对象。
给定一个文本prompt,Re-Imagen通过访问外部知识库(图文对)检索相关的内容,然后将该内容作为参考生成图像。通过该过程,Re-Imagen由于高层的语义信息和低层的视觉细节信息对生成过程进行了增强。此外,为了平衡文本对齐和检索内容的对齐,作者利用了一种新的采样策略去混合文本条件和检索条件的classifier-free guidance。
最后为了更全面地评测模型的能力,作者提出了EntityDrawBench,一个新的基准用于评价多种对象的图像生成能力,从常见到罕见。
具体来说,Re-Imagen将检索到的内容经过同样的Unet的编码阶段得到特征,然后与原特征进行cross-attention操作,从而将检索的信息融合进模型。
