- 文章标题:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
- 文章地址:https://arxiv.org/abs/2205.11487
- NIPS 2022
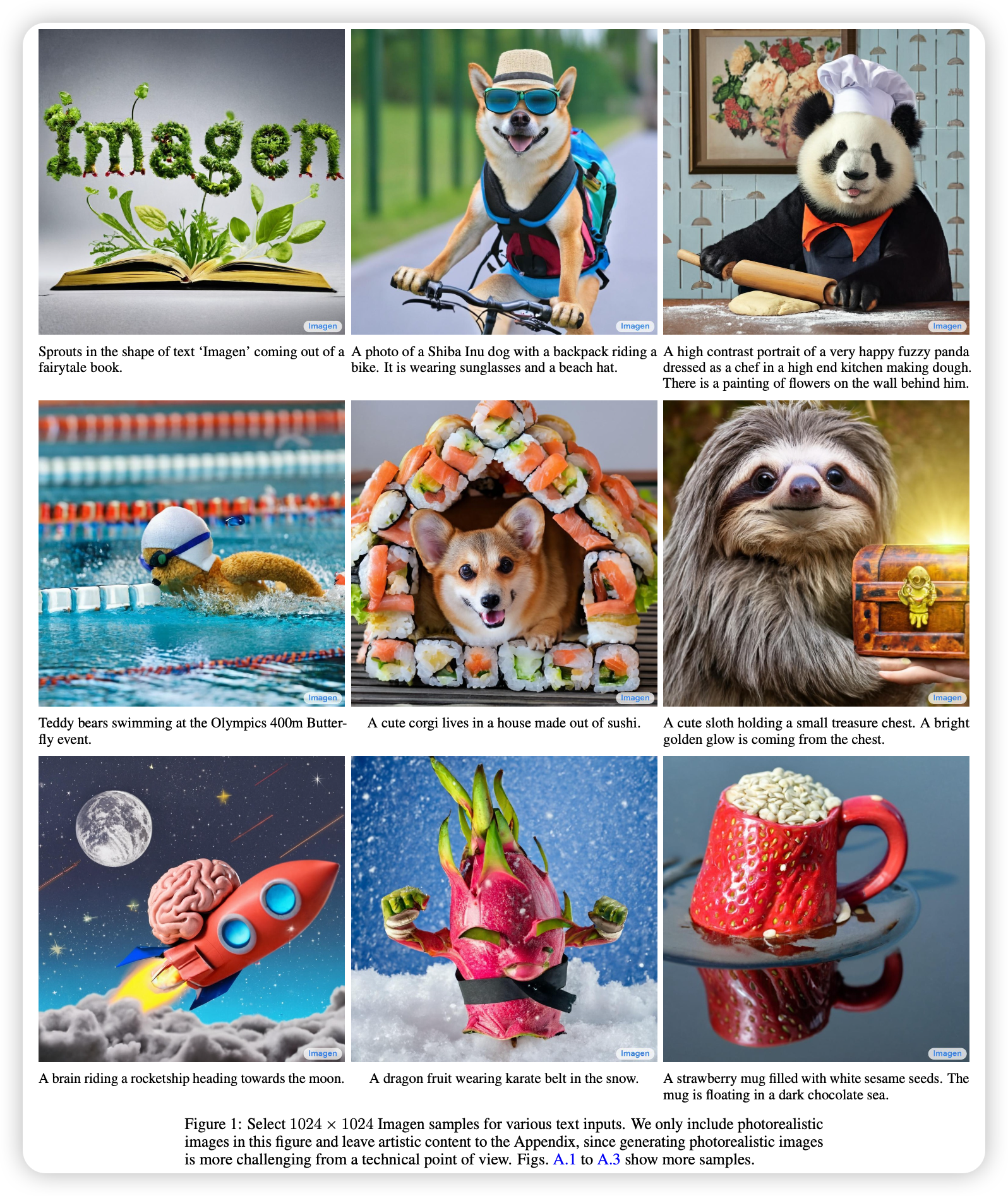
 文章提出了Imagen,一个具有空前真实性和高层语言理解的文生图扩散模型。
模型建立在大语言模型的语言理解能力和扩散模型的高质量图片生成能力上。作者发现,仅用文本训练的通用的大语言模型(如T5)在文生图的文本编码上非常有效,且增加语言模型的尺寸比增加扩散模型的尺寸在生成图片的质量和文本对齐度上更有效。
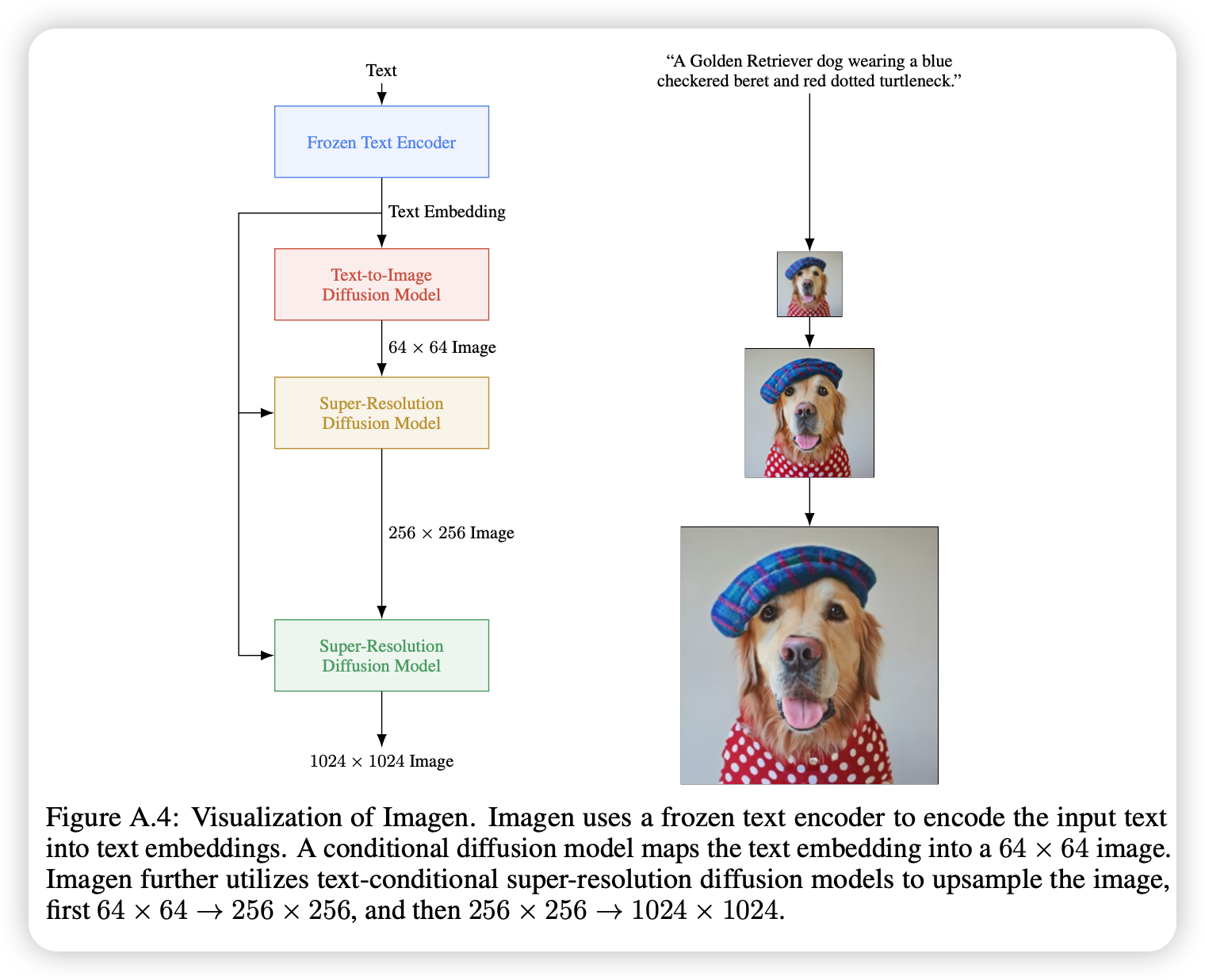
为了更好地评测文生图模型,文章提出了DrawBench,一个文生图的全面且具有挑战的基准。且Imagen具有两个级联的扩散模型用于增加图片的分辨率(64-256-1024),模型的base使用的是U-Net。
文章提出了Imagen,一个具有空前真实性和高层语言理解的文生图扩散模型。
模型建立在大语言模型的语言理解能力和扩散模型的高质量图片生成能力上。作者发现,仅用文本训练的通用的大语言模型(如T5)在文生图的文本编码上非常有效,且增加语言模型的尺寸比增加扩散模型的尺寸在生成图片的质量和文本对齐度上更有效。
为了更好地评测文生图模型,文章提出了DrawBench,一个文生图的全面且具有挑战的基准。且Imagen具有两个级联的扩散模型用于增加图片的分辨率(64-256-1024),模型的base使用的是U-Net。