- 文章标题:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- 文章地址:https://arxiv.org/abs/2208.01618
- ICLR 2023
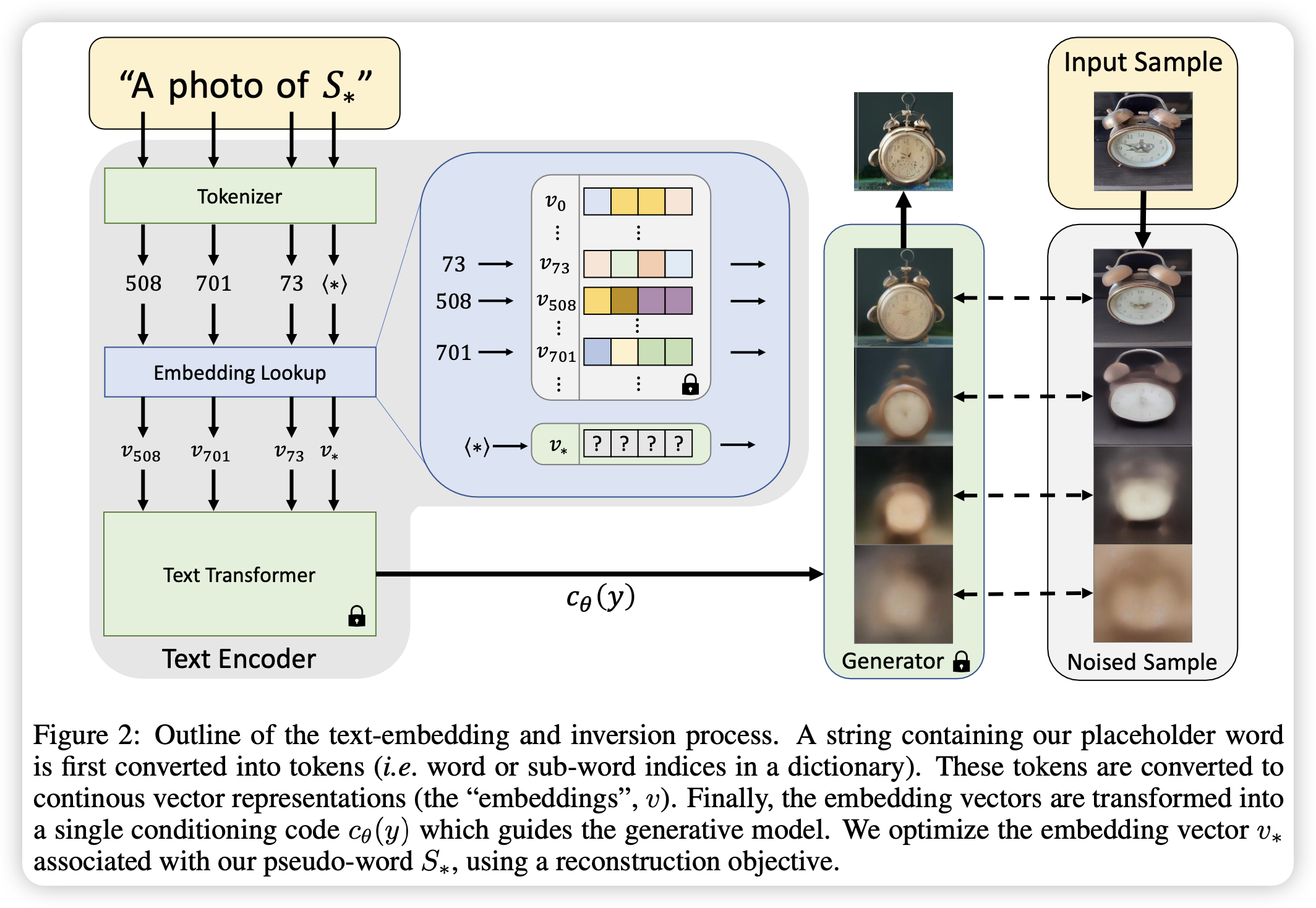 利用图片进行定制化文生图的开山之作。
现有的文生图没办法生成自己想要的某个对象的图片,文章提出了一种方法,用户提供3-5张特定对象的图片,学习该对象在embedding空间的值,对应词S*,从而用户可以使用S*来表达该特定的对象。并且文章指出,仅使用一个词来代表一个特定对象是足够的。方法非常简单有效,就是训练了一个embedding。
利用图片进行定制化文生图的开山之作。
现有的文生图没办法生成自己想要的某个对象的图片,文章提出了一种方法,用户提供3-5张特定对象的图片,学习该对象在embedding空间的值,对应词S*,从而用户可以使用S*来表达该特定的对象。并且文章指出,仅使用一个词来代表一个特定对象是足够的。方法非常简单有效,就是训练了一个embedding。
