- 文章标题:VICO : PLUG-AND-PLAY VISUAL CONDITION FOR PERSONALIZED TEXT-TO-IMAGE GENERATION
- 文章地址:https://arxiv.org/abs/2306.00971
- arxiv
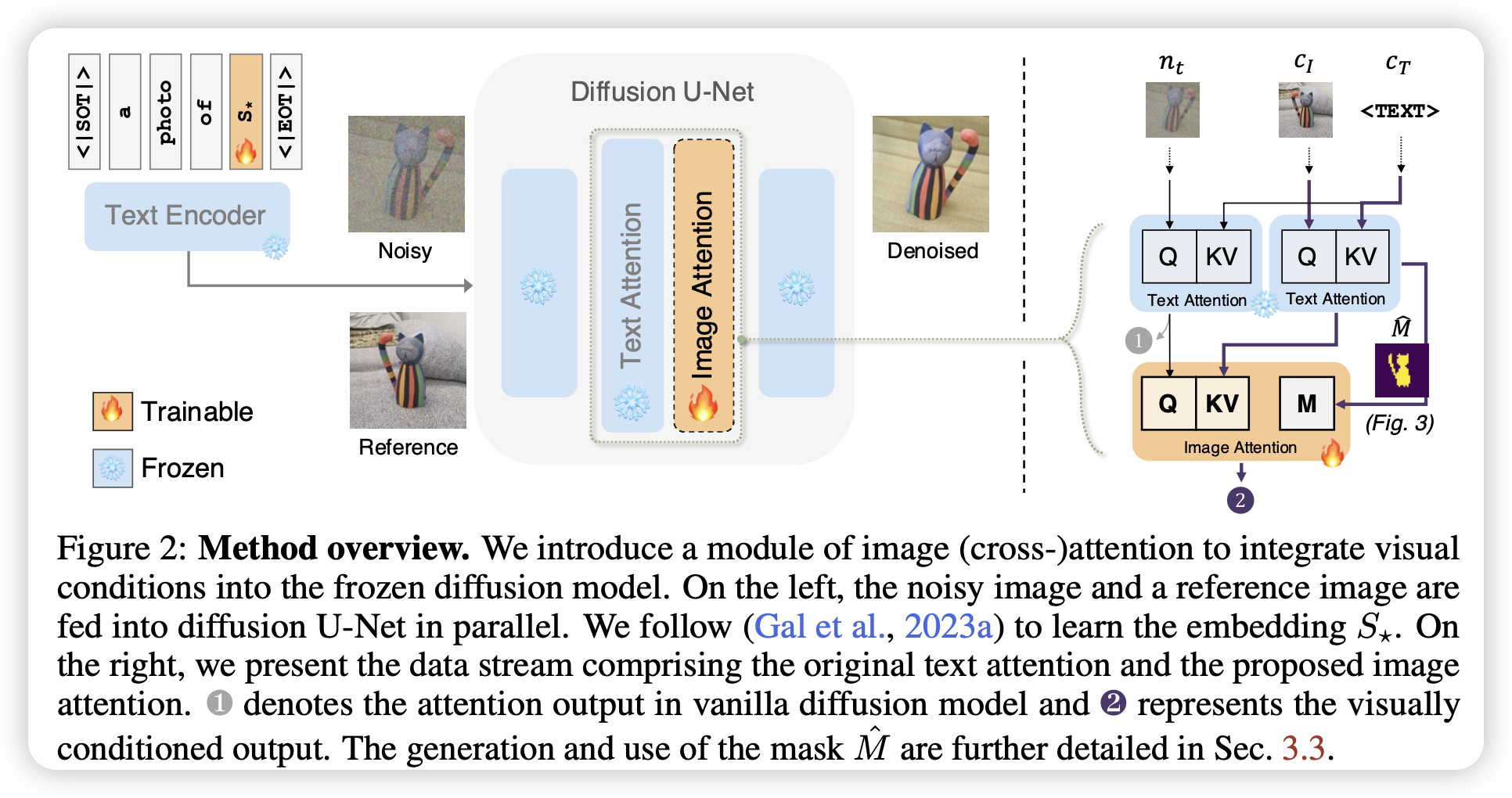 有一个地方存在疑问。那个CI是怎么来的?
文章提出了ViCo,一个全新的轻量化的即插即用的方法,用于无缝地将视觉条件加入到定制化文生图中。其特点跟lora很像(感觉就跟lora一样),不需要微调原来的参数,提供了高灵活和高扩展性。具体来说,ViCo使用了一个图像注意力模块,将图像的语义信息融合进了扩散过程,并且使用了基于注意力的掩码(不需额外计算)。
有一个地方存在疑问。那个CI是怎么来的?
文章提出了ViCo,一个全新的轻量化的即插即用的方法,用于无缝地将视觉条件加入到定制化文生图中。其特点跟lora很像(感觉就跟lora一样),不需要微调原来的参数,提供了高灵活和高扩展性。具体来说,ViCo使用了一个图像注意力模块,将图像的语义信息融合进了扩散过程,并且使用了基于注意力的掩码(不需额外计算)。

- 数据:参考图像训练
- 指标:DINO;CLIP;训练/推理时间
- 硬件:未提及
- 开源:https://github.com/haoosz/ViCo