- 文章标题:DIFFUSION MODELS ALREADY HAVE A SEMANTIC LATENT SPACE
- 文章地址:https://arxiv.org/abs/2210.10960
- ICLR 2023
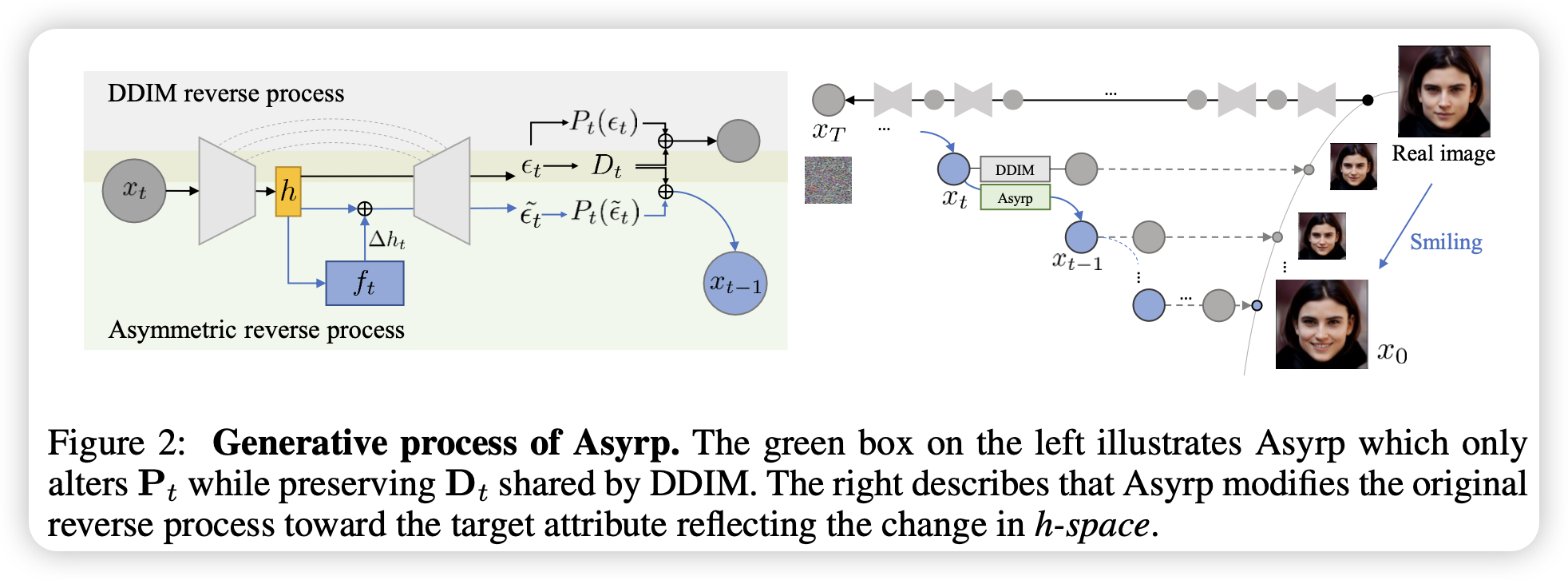 作者提出了一个非对称的扩散模型的反向过程,得到了预训练扩散模型的语义空间(h-soace),具有很好的图像编辑的特性:同质性、线性、鲁棒性、连续性等等。可以对某个特性(如微笑)训练一个轻量网络f,通过该网络对该特性进行调整(笑或不笑)。
文章将去噪过程形式化为:
作者提出了一个非对称的扩散模型的反向过程,得到了预训练扩散模型的语义空间(h-soace),具有很好的图像编辑的特性:同质性、线性、鲁棒性、连续性等等。可以对某个特性(如微笑)训练一个轻量网络f,通过该网络对该特性进行调整(笑或不笑)。
文章将去噪过程形式化为:
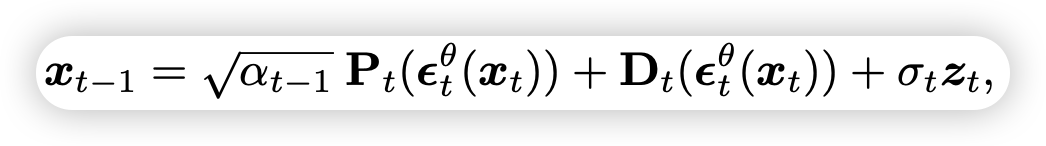 要想在语义空间对图像的生成进行编辑,其中一个方法为对预测的噪声ε进行偏移,但这无法对生成图像造成改变,因为噪声对P和D的影响相互抵消(证明见原文)。因此,作者提出了非对称去噪的方法:
要想在语义空间对图像的生成进行编辑,其中一个方法为对预测的噪声ε进行偏移,但这无法对生成图像造成改变,因为噪声对P和D的影响相互抵消(证明见原文)。因此,作者提出了非对称去噪的方法:
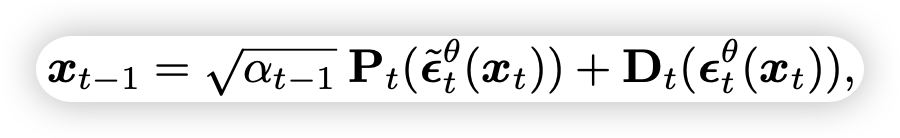 即对P中预测的噪声进行偏移,保留D中的噪声。
作者通过在U-Net的最深层引入偏移量Δh来对噪声进行偏移,其通过一个轻量网络进行预测,得到了h-space,具有一些很好的特性:同样的Δh对不同的采样图片具有同样的影响;可以做到线性改变该特性,甚至负数得到反特性;多个Δh叠加可得到多个特性融合;不改变原来采样结果的图片质量;Δh在不同的时间步大致一致。
即对P中预测的噪声进行偏移,保留D中的噪声。
作者通过在U-Net的最深层引入偏移量Δh来对噪声进行偏移,其通过一个轻量网络进行预测,得到了h-space,具有一些很好的特性:同样的Δh对不同的采样图片具有同样的影响;可以做到线性改变该特性,甚至负数得到反特性;多个Δh叠加可得到多个特性融合;不改变原来采样结果的图片质量;Δh在不同的时间步大致一致。