- 文章标题:Adding Conditional Control to Text-to-Image Diffusion Models
- 文章地址:https://arxiv.org/abs/2302.05543
- ICCV 2023
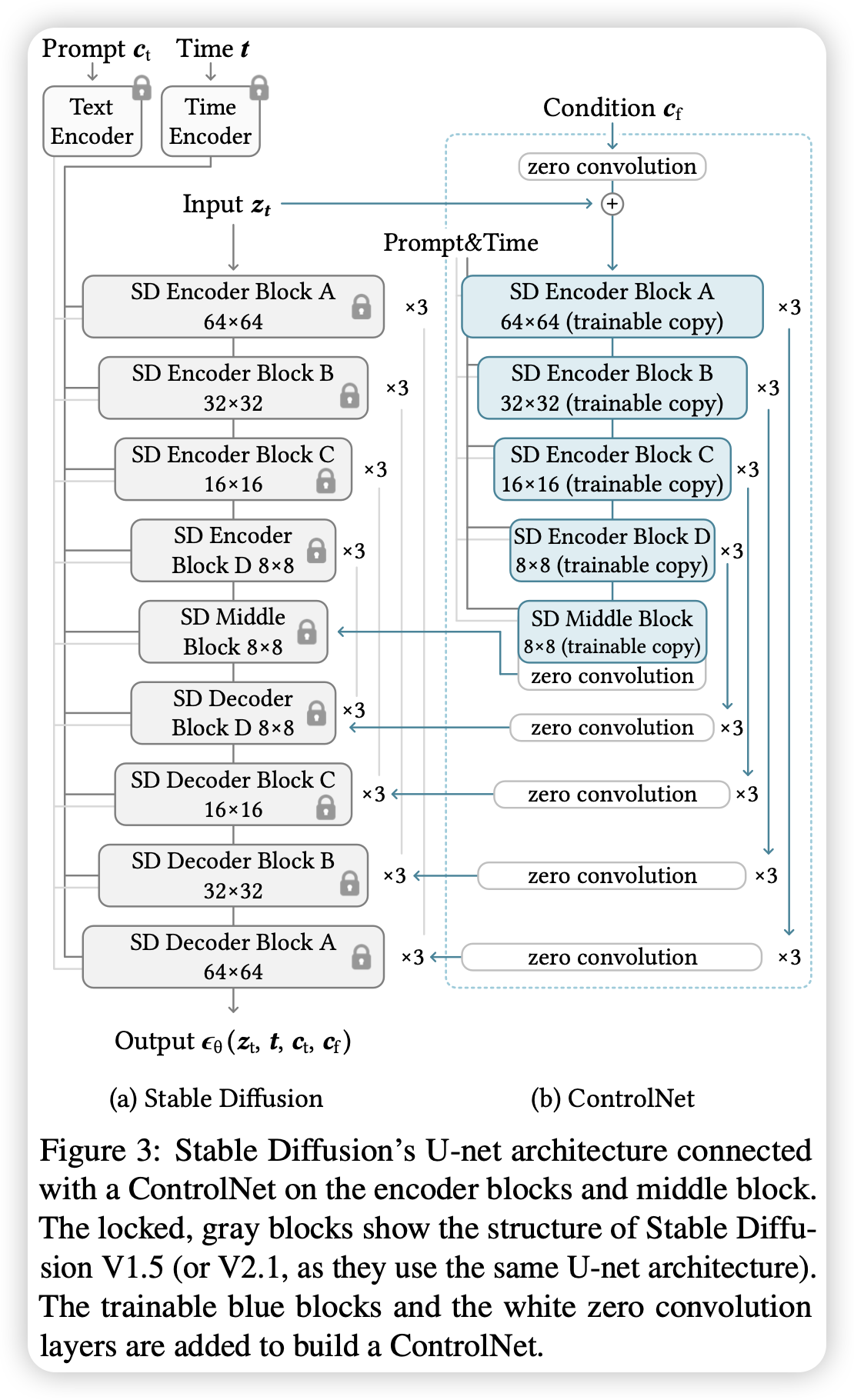 作者提出了ControlNet,可以对预训练的文生图模型引入空间布局条件的控制,其通过训练一个源模型的复制品,称为ControlNet,其通过zero convolution layer(即初始化为0的卷积层)与源模型连接。零卷积层的参数从0逐渐增加,确保没有噪声影响整个微调过程。模型在边缘图、深度图、分割图和人体姿势图等等表现都很好,做到了布局条件下的图片生成。
主图中为Stable Diffusion下的ControlNet结构,其训练了U-Net中的Encoder和Middle Block的复制。
作者提出了ControlNet,可以对预训练的文生图模型引入空间布局条件的控制,其通过训练一个源模型的复制品,称为ControlNet,其通过zero convolution layer(即初始化为0的卷积层)与源模型连接。零卷积层的参数从0逐渐增加,确保没有噪声影响整个微调过程。模型在边缘图、深度图、分割图和人体姿势图等等表现都很好,做到了布局条件下的图片生成。
主图中为Stable Diffusion下的ControlNet结构,其训练了U-Net中的Encoder和Middle Block的复制。