- 文章标题:IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
- 文章地址:https://arxiv.org/abs/2308.06721
- arxiv
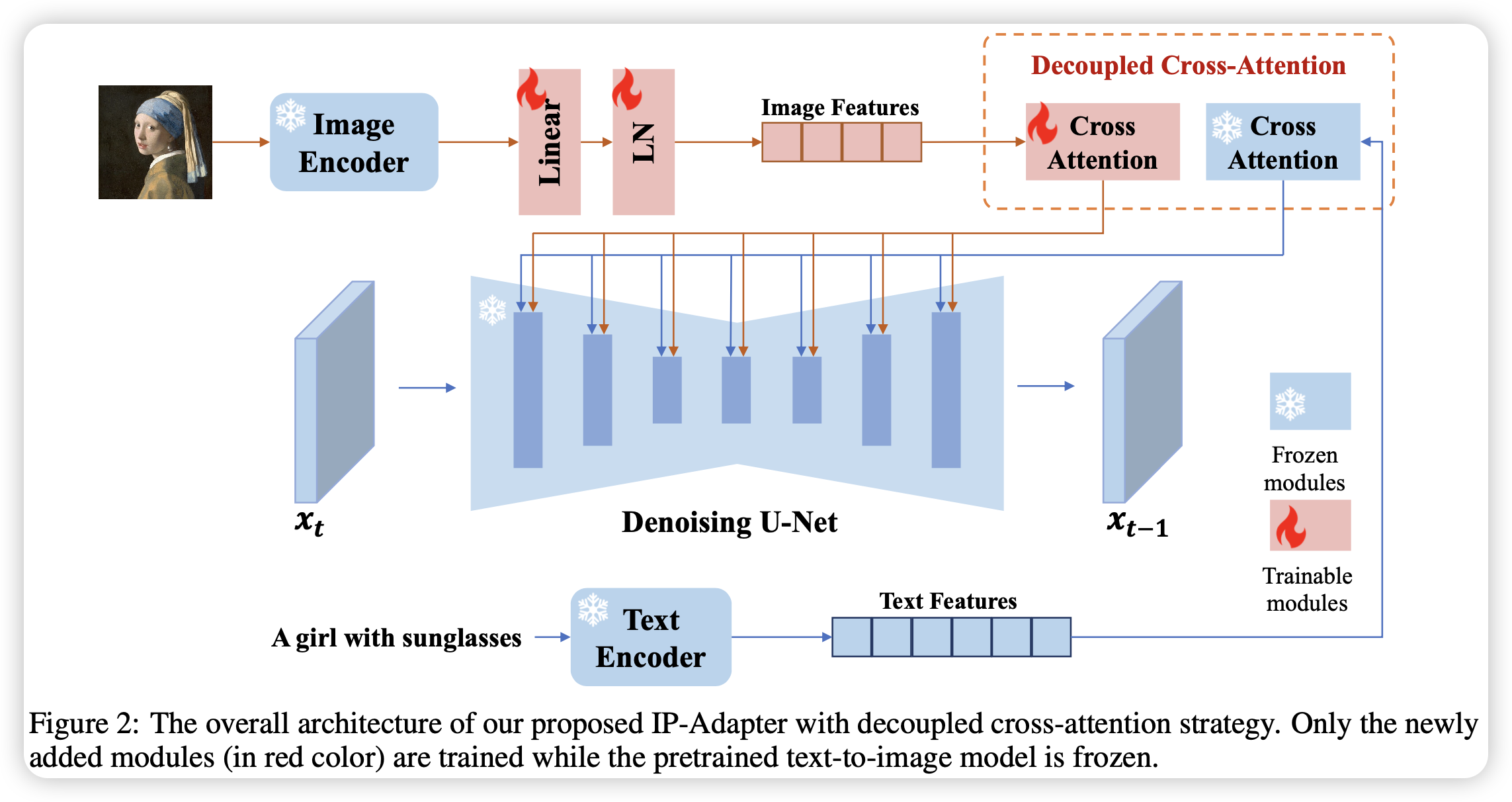 文章的出发点非常简单,就是将图片作为prompt引入文生图的模型中。实现也非常简单,将图片经过CLIP编码得到特征,然后经过映射形成N个特征,随后引入新的交叉注意力层将图片特征融合到U-Net中(图片与文本分别与隐变量做交叉注意力然后加权求和)。
文章的出发点非常简单,就是将图片作为prompt引入文生图的模型中。实现也非常简单,将图片经过CLIP编码得到特征,然后经过映射形成N个特征,随后引入新的交叉注意力层将图片特征融合到U-Net中(图片与文本分别与隐变量做交叉注意力然后加权求和)。