- 文章标题:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- 文章地址:https://arxiv.org/abs/2208.12242
- CVPR 2023
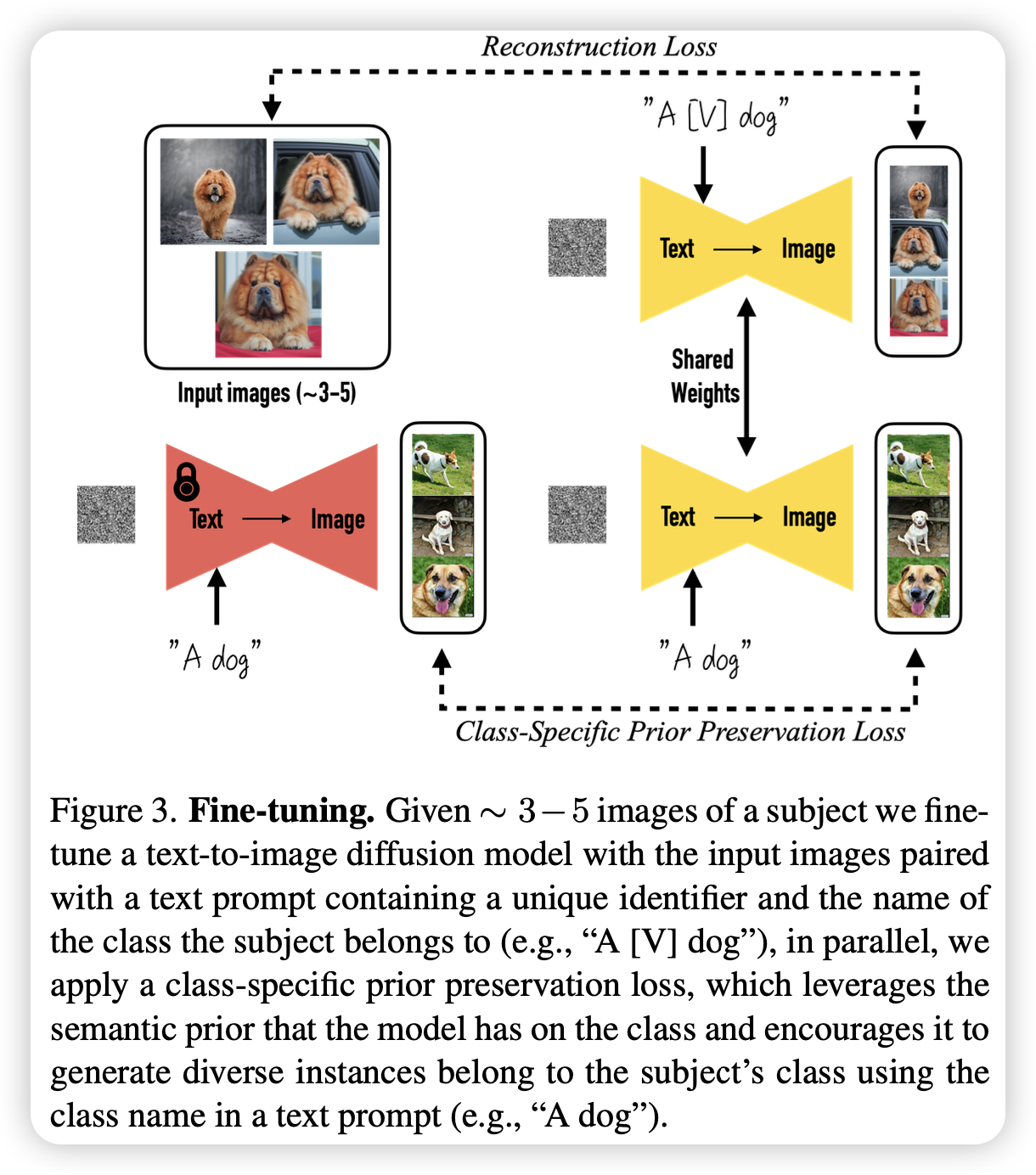 定制化文生图的经典之作。作者指出,当前文生图模型可以得到高质量和多样化的图片,但缺少从一张图片中复刻对象并生成该对象在不同文本条件下的图片的能力。因此文章提出了一种新的方法,用于定制化文生图。给定某对象的一些图片,微调一个预训练的文生图模型使其将该对象与一个特殊的标识符相对应。
当该对象被嵌入到模型的输出范围内,可以使用该标识符在不同的场景中来生成该对象。模型可以生成多角度、多场景、多光照条件、多姿势的对象。值得注意的是,该方法的损失函数还加上了先验信息保留的部分,用于保留多样性以及防止语言飘移。
定制化文生图的经典之作。作者指出,当前文生图模型可以得到高质量和多样化的图片,但缺少从一张图片中复刻对象并生成该对象在不同文本条件下的图片的能力。因此文章提出了一种新的方法,用于定制化文生图。给定某对象的一些图片,微调一个预训练的文生图模型使其将该对象与一个特殊的标识符相对应。
当该对象被嵌入到模型的输出范围内,可以使用该标识符在不同的场景中来生成该对象。模型可以生成多角度、多场景、多光照条件、多姿势的对象。值得注意的是,该方法的损失函数还加上了先验信息保留的部分,用于保留多样性以及防止语言飘移。
