- 文章标题:Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models
- 文章地址:https://arxiv.org/abs/2302.12228
- TOG 2023
 比较难懂,还需精读。
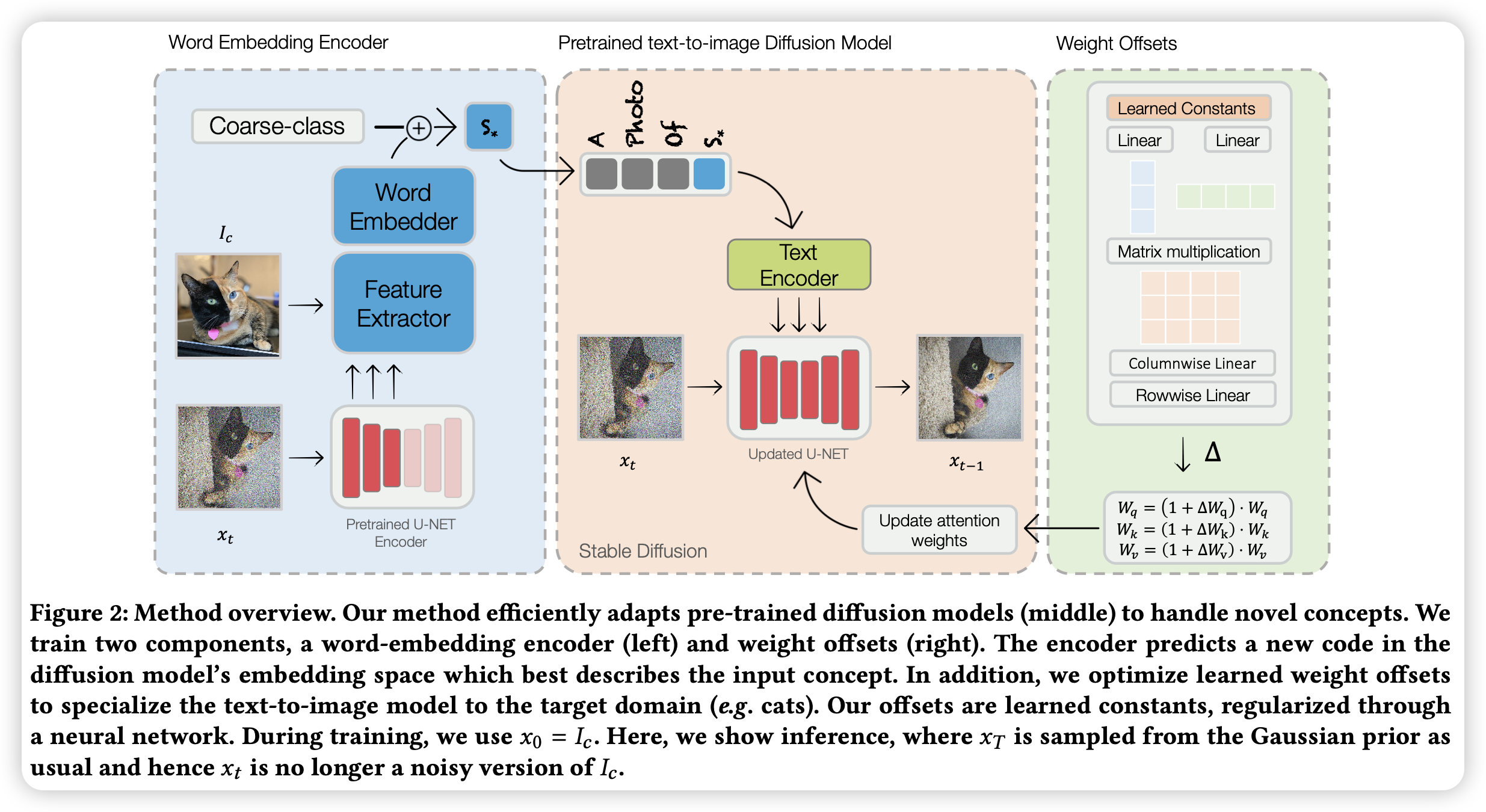
当前的定制化文生图需要大量的训练时间、存储空间或有一定的身份损失。为了解决这些问题,文章提出了一个基于编码器的域适应的方法。文章的关键思想为,通过对给定领域的大量概念进行不足的拟合,我们可以提高泛化能力,并创建一个更适合从同一领域快速添加新概念的模型。具体来说,方法包含两个部分:首先是一个目标域的特定对象的图片编码器,然后将其映射到词空间中代表该对象;其次是模型中正则化的权重偏移的集合,用于学习如何有效地处理增加的对象。两个部分共同运作,可以使文生图模型在对单张对象图片训练仅仅5步左右后,具备该对象的定制化文生图的能力。
比较难懂,还需精读。
当前的定制化文生图需要大量的训练时间、存储空间或有一定的身份损失。为了解决这些问题,文章提出了一个基于编码器的域适应的方法。文章的关键思想为,通过对给定领域的大量概念进行不足的拟合,我们可以提高泛化能力,并创建一个更适合从同一领域快速添加新概念的模型。具体来说,方法包含两个部分:首先是一个目标域的特定对象的图片编码器,然后将其映射到词空间中代表该对象;其次是模型中正则化的权重偏移的集合,用于学习如何有效地处理增加的对象。两个部分共同运作,可以使文生图模型在对单张对象图片训练仅仅5步左右后,具备该对象的定制化文生图的能力。

- 数据:人脸(FFHQ)、猫(LSUN-Cat)
- 指标:人脸相似度(某篇论文的,具体看原文);文本对齐度(CLIP)
- 硬件:1 A100/bs16
- 开源:https://tuning-encoder.github.io